
Web Scraping mit Objektnotation
April 1, 2020
6 Lesezeit

Sie möchten Daten abrufen, die nicht über REST oder Webdienste verfügbar sind? Was, wenn sie nur auf einer Website verfügbar sind? Die Daten sind für einen Menschen einfach genug zu lesen, aber das Lesen von HTML-Daten mit einer Programmiersprache ist nicht so einfach. Einige Entwickler versuchen es mit Position und Substring, andere mit Regex, aber das ist unangenehm und zeitraubend. Ein ganz anderer Ansatz besteht darin, das HTML in ein Objekt zu konvertieren und die Daten über die Objektnotation zu erhalten. Tabellenzeilen werden als Sammlungen behandelt und lassen sich leicht in Schleifen durchlaufen!
In diesem Blogbeitrag wird beschrieben, wie man diesen Ansatz verwendet, und es werden einige praktische Tipps gegeben.
HDI: Web Scraping mit Objekten
In unserem ersten Beispiel beginnen wir mit der Homepage unseres Blogs: https://blog.4d.com. Unsere Aufgabe ist es, diese Seite zu analysieren und die Liste der Blog-Einträge in einer Listbox mit Spalten für Autor, Bild, Titel und Inhalt anzuzeigen:
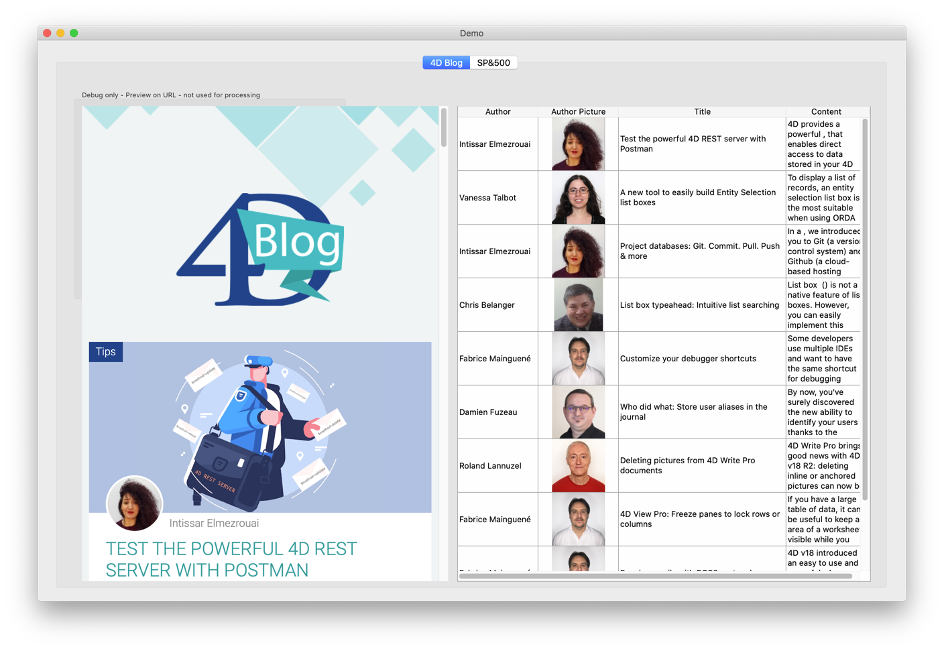
Die Demoanwendung zeigt die Webseite in einem Webbereich auf der linken Seite, um sie zu vergleichen und zu testen (in einer echten Anwendung würden wir das natürlich nicht zeigen).
Öffnen Sie die Methode Demo_RunBlog, um zu sehen, wie sie funktioniert. Hier sind die wichtigsten Schritte:
$url:="https://blog.4d.com"
$status :=HTTP Get($url;$answer)
Die erste Aufgabe besteht darin, den HTML-Inhalt in eine Textvariable zu laden. HTML ist sehr tolerant; es wird auch dann noch korrekt angezeigt, wenn es voller Fehler wie fehlender schließender Tags(z. B. ein fehlendes </p>) oder ähnlicher Syntaxprobleme ist. Dies erschwert jedoch die Analyse, da jeder öffnende Tag den erwarteten schließenden Tag haben kann oder auch nicht.
Die gute Nachricht ist, dass es ein Tool gibt, das solche Probleme behebt, es heißt „tidy“. Es ist sowohl für Mac als auch für Windows verfügbar und kann in eine 4D Anwendung eingebettet und mit dem Befehl LAUNCH EXTERNAL PROCESS aufgerufen werden.
Wir verwenden es hier:
$answertidy:=RunTidy ($answer) // make it conform to XML
Wenn Sie neugierig sind, können Sie sich den Inhalt von XMLToObject ansehen, um zu sehen, wie er funktioniert, aber es ist nicht notwendig, ihn zu verwenden. Sobald sich der Inhalt in einem Objekt befindet, können wir die Objektnotation verwenden, um direkt auf die Elemente zuzugreifen:
$articles:=$html.body.div[0].div.div.div[0].div.article )
$blogposts :=New collection // collect the data
For each ($article;$articles)
$authorurl :=String($article.div[0].div[0].div.img.src)
$authorname :=String($article.div[0].div[0].span.a.__value)
$title :=String($article.div[0].span[1].a.title)
...
$blogposts .push(New object("author";$authorname; "picturl";$authorurl; "pict";$pict; "title";$title; "content";$content)
End for each
Es sieht zwar recht einfach aus, aber die Herausforderung besteht darin, die Position des Objekts zu kennen. Sobald wir dies wissen, ist die Eingabe der Position (z. B..body.div[0]…div.article) einfach.
Um festzustellen, wie eine Webseite aufgebaut ist, zeigen Sie sie in einem Browser an und öffnen Sie den Debugger oder Inspektor des Webbrowsers:
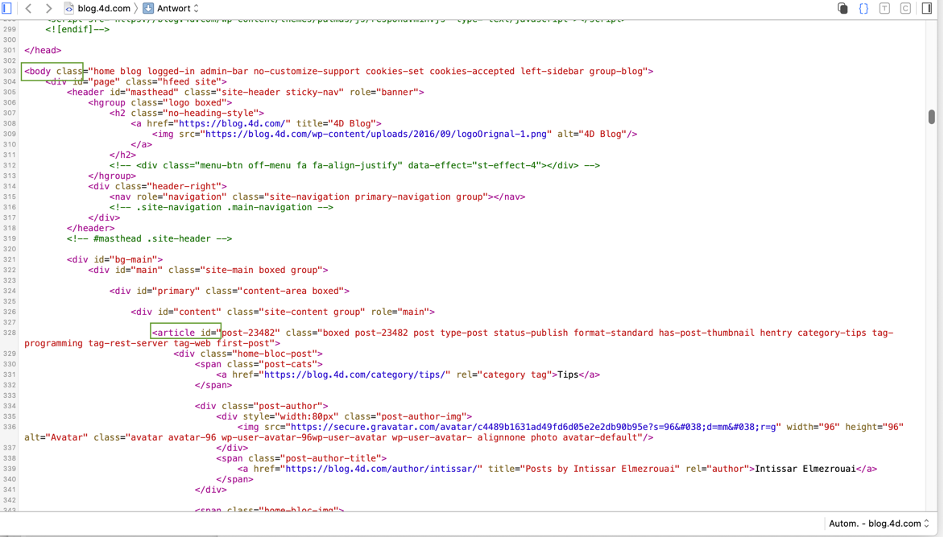
In diesem Beispiel müssen wir den Pfad von „body“ zu „article„(d. h. dem ersten Blogartikel) finden. Der Debugger liefert zwar Hinweise, aber die Suche nach dem Pfad ist immer noch schwierig. Es wäre einfacher, wenn wir ihn direkt als hierarchische Liste formatieren könnten, also verfolgen wir die Methode und setzen den Ausführungszeiger auf den Block False:
If (False) // this helps find the path in the object
SET TEXT TO PASTEBOARD (JSON Stringify($html;*))
End if
Selbst in einem Texteditor ist der Text schwer zu lesen, aber Tools wie VisualJSON oder Notepad++ (mit der JSONViewer-Erweiterung) sind sehr hilfreich! So sieht es in VisualJSON aus:
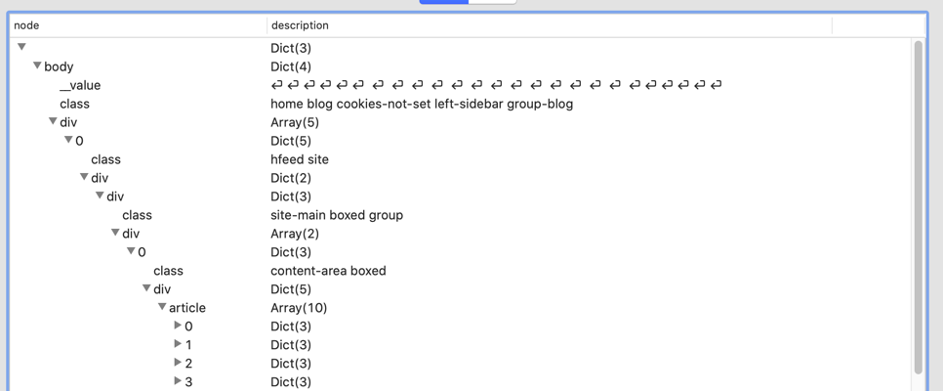
Dies zeigt den Pfad zu body.div[0].div.div.div[0].div.article.
Der Debugger von 4D liefert eine ähnliche Liste:
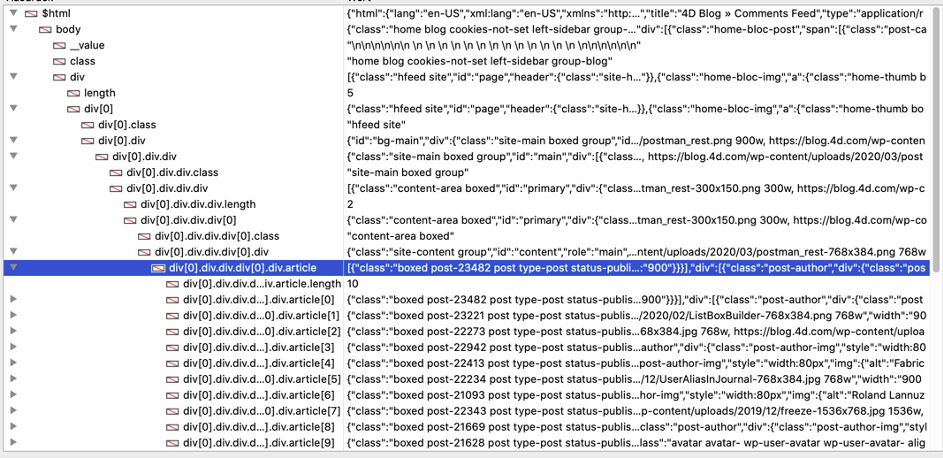
„Artikel“ ist eine Sammlung und jedes Element enthält einen einzelnen Blogbeitrag. Wir können mit For Each eine Schleife durch die Sammlung ziehen und auf die erforderlichen Felder zugreifen. „image“ ist ein Standard-HTML-Bild und src enthält die URL, so dass wirdie URL erhalten und HTTP Get verwenden, um das Bild herunterzuladen. Schließlich erstellt die Methode das Listenfeld und passt es an, um die Daten anzuzeigen.
In unserem zweiten Beispiel rufen wir Daten aus einer Tabelle auf Wikipedia ab:
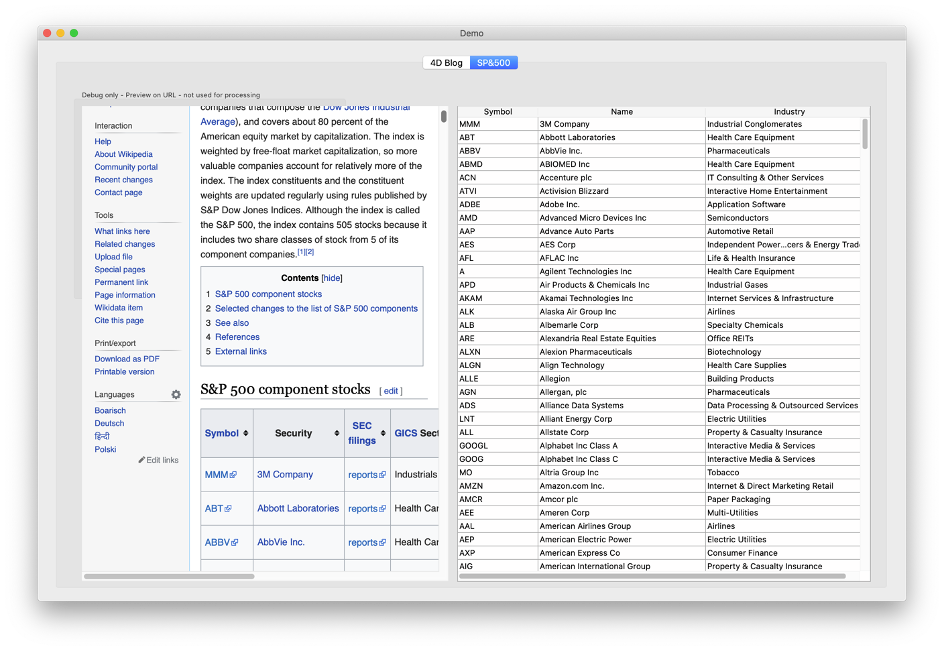
Lesen Sie die Methode Demo_RunSP500, um den Code zu analysieren.
Wir folgen dem gleichen Muster:
Wir werden einen kleinen Trick anwenden, um den Objektpfad zu finden, da die Seite komplex ist und mehrere Tabellen enthält (was die Verwendung eines normalen Pfades unmöglich macht). Was ist also der Trick? Reduzieren Sie den Inhalt, indem Sie das erste „tbody“-Element verwenden:
$pos:=Position("<tbody>";$answertidy)
$answertidy :=Substring($answertidy;$pos)
$pos :=Position("</tbody>";$answertidy)
$answertidy :=Substring($answertidy;1;$pos+8)Dann wandeln wir den reduzierten Text einfach in ein Objekt um. Viel einfacher!
Um diese Abkürzung zu finden, öffnen wir die Seite mit einem Browser und überprüfen den Quelltext, um die Elemente zu finden, an denen wir wirklich interessiert sind. In diesem Beispiel ist es die erste Tabelle. Andernfalls hätten wir nach einem eindeutigen Element gesucht, wie zum Beispiel: <table class=“wikitable sortable“ id=“constituents“>.
Das Element mit dem <tbody>-Tag ist das, was wir brauchen. Dank des reduzierten Inhalts können wir mit diesem Code auf die Tabellenzeilen zugreifen:
$list$stocktd:=$html.tbody.tr // a collection of table rows
For each ($stock;$list)
$curstock :=New object
If
($stock.th[0]#Null) // ignore the header
Else
$curstock .symbol:=$stock.td[0].a.__value
$curstock .name:=$stock.td[1].a.__value
$curstock .industry__value
$allstocks.push($curstock)
End if
End for each
Vergessen Sie nicht, den Debugger von 4D zu verwenden, der Ihnen ebenfalls hilft, die benötigten Elemente zu finden:

Wenn Sie schon einmal versucht haben, eine HTML-Seite mit Position/Substring oder Regex zu parsen, werden Sie die Vorteile der in diesem Blog-Beitrag beschriebenen Techniken leicht erkennen. Wenn Sie noch nie HTML-Inhalte analysieren mussten, könnte es anfangs eine kleine Herausforderung sein, aber bleiben Sie dran! Es eröffnet neue Datenquellen und neue Möglichkeiten, verfügbare Daten direkt in Ihren Anwendungen abzurufen und zu nutzen.
Sie haben eine Frage, eine Anregung oder möchten einfach nur mit den 4D Bloggern in Kontakt treten? Schreiben Sie uns eine Nachricht!
* Ihre Privatsphäre ist uns sehr wichtig. Bitte klicken Sie hier, um unsere Politik
Für diesen Beitrag sind derzeit keine Kommentare verfügbar.