
Scraping del web con notazione a oggetti
Aprile 1, 2020
5 Tempo di lettura

Volete recuperare dati che non sono disponibili tramite REST o servizi Web? E se sono disponibili solo su un sito web? I dati sono abbastanza facili da leggere per un essere umano, ma leggere i dati HTML con un linguaggio di programmazione non è così semplice. Alcuni sviluppatori cercano di usare Position e Substring, altri provano con Regex, ma è spiacevole e richiede molto tempo. Un approccio molto diverso è quello di convertire l’HTML in un oggetto e ottenere i dati tramite la notazione degli oggetti. Le righe delle tabelle vengono gestite come collezioni e sono facili da analizzare!
Questo post del blog descrive come utilizzare questo approccio e fornisce alcuni suggerimenti utili.
HDI: Web Scraping con gli oggetti
Nel nostro primo esempio, inizieremo con la homepage del nostro blog: https://blog.4d.com. Diciamo che il nostro compito è analizzare questa pagina e visualizzare l’elenco dei post del blog in una casella di riepilogo con colonne per autore, immagine, titolo e contenuto:
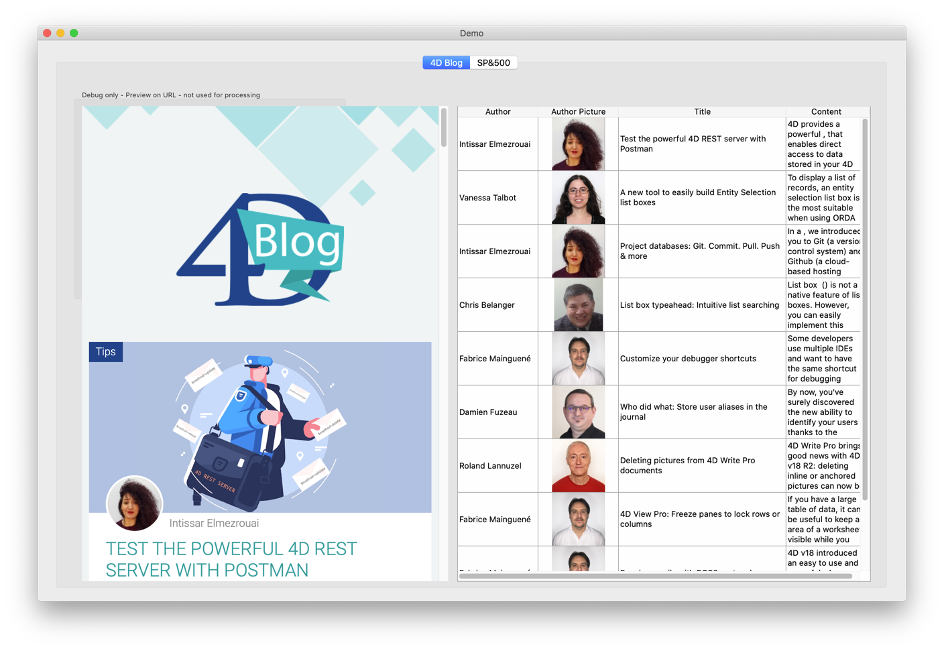
L’applicazione dimostrativa mostra la pagina web in un’area web a sinistra, per poterla confrontare e testare (in un’applicazione reale, ovviamente, non la mostreremmo).
Aprire il metodo Demo_RunBlog per vedere come funziona. Ecco i passaggi importanti:
$url:="https://blog.4d.com"
$status :=HTTP Get($url;$answer)
Il primo compito è quello di caricare il contenuto HTML in una variabile di testo. L’HTML è molto tollerante; verrà visualizzato correttamente anche se è pieno di errori, come tag di chiusura mancanti(ad esempio, un </p> mancante) o problemi di sintassi simili. Tuttavia, questo rende difficile l’analisi, poiché ogni tag di apertura può avere o meno il tag di chiusura previsto.
La buona notizia è che esiste uno strumento per correggere problemi di questo tipo, chiamato “tidy”. Disponibile sia per Mac che per Windows, può essere incorporato in un’applicazione 4D e richiamato con il comando LAUNCH EXTERNAL PROCESS.
Lo usiamo qui:
$answertidy:=RunTidy ($answer) // make it conform to XML
Se siete curiosi, potete controllare il contenuto di XMLToObject se volete vedere come funziona, ma non è necessario usarlo. Una volta che il contenuto è in un oggetto, possiamo usare la notazione degli oggetti per accedere direttamente agli elementi:
$articles:=$html.body.div[0].div.div.div[0].div.article )
$blogposts :=New collection // collect the data
For each ($article;$articles)
$authorurl :=String($article.div[0].div[0].div.img.src)
$authorname :=String($article.div[0].div[0].span.a.__value)
$title :=String($article.div[0].span[1].a.title)
...
$blogposts .push(New object("author";$authorname; "picturl";$authorurl; "pict";$pict; "title";$title; "content";$content)
End for each
Anche se sembra abbastanza semplice, la sfida sta nel conoscere la posizione dell’oggetto. Non appena la si conosce, digitare la posizione (ad esempio.body.div[0]…div.article) è facile.
Per determinare come è costruita una pagina web, basta visualizzarla in un browser e aprire il debugger o l’inspector del browser:
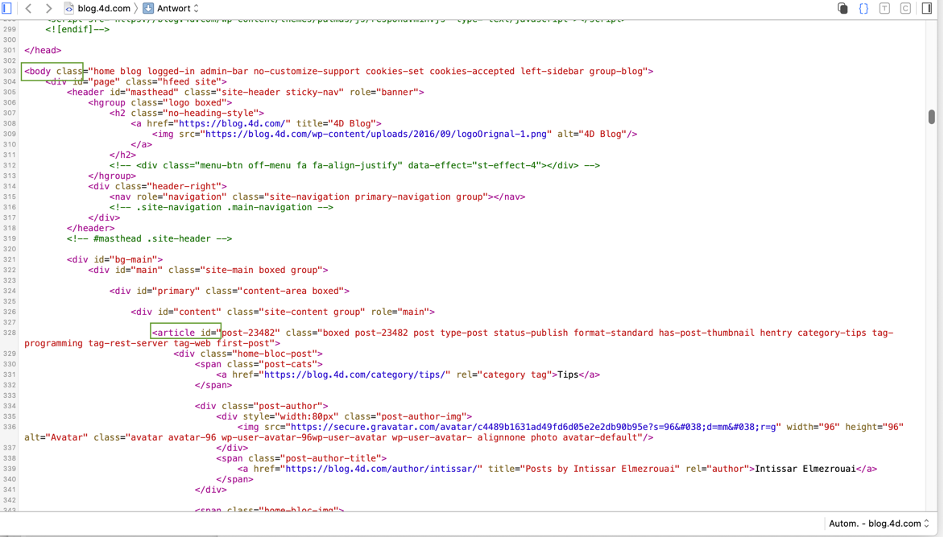
In questo esempio, dobbiamo trovare il percorso da “body” a “article“(cioè il primo articolo del blog). Il debugger fornisce degli indizi, ma trovare il percorso è ancora difficile. Sarebbe più facile se potessimo formattarlo direttamente come elenco gerarchico, quindi tracceremo il metodo e imposteremo il puntatore di esecuzione al blocco False:
If (False) // this helps find the path in the object
SET TEXT TO PASTEBOARD (JSON Stringify($html;*))
End if
Anche in un editor di testo, il testo è difficile da leggere, ma strumenti come VisualJSON o Notepad++ (con l’estensione JSONViewer) aiutano molto! Ecco come appare in VisualJSON:
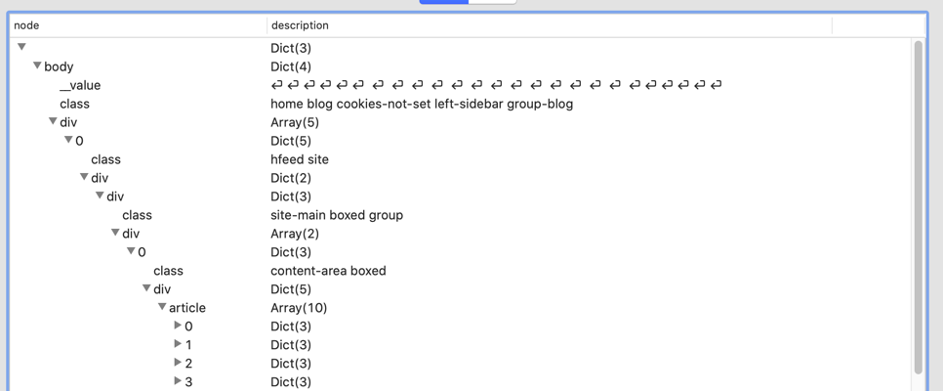
Questo mostra il percorso di body.div[0].div.div[0].div.article.
Il debugger di 4D fornisce un elenco simile:
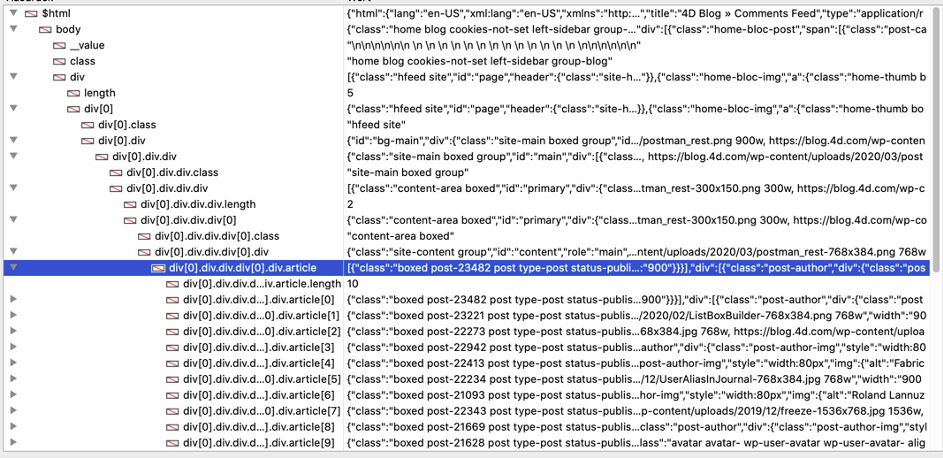
“Article” è una collezione e ogni elemento contiene un singolo post del blog. Possiamo scorrere l’insieme con For Each e accedere ai campi richiesti.“image” è un’immagine HTML standard e src contiene l’URL, quindi otteniamo l’URL e usiamo HTTP Get per scaricare l’immagine. Infine, il metodo costruisce e regola la casella di riepilogo per visualizzare i dati.
Nel secondo esempio, recuperiamo i dati da una tabella di Wikipedia:
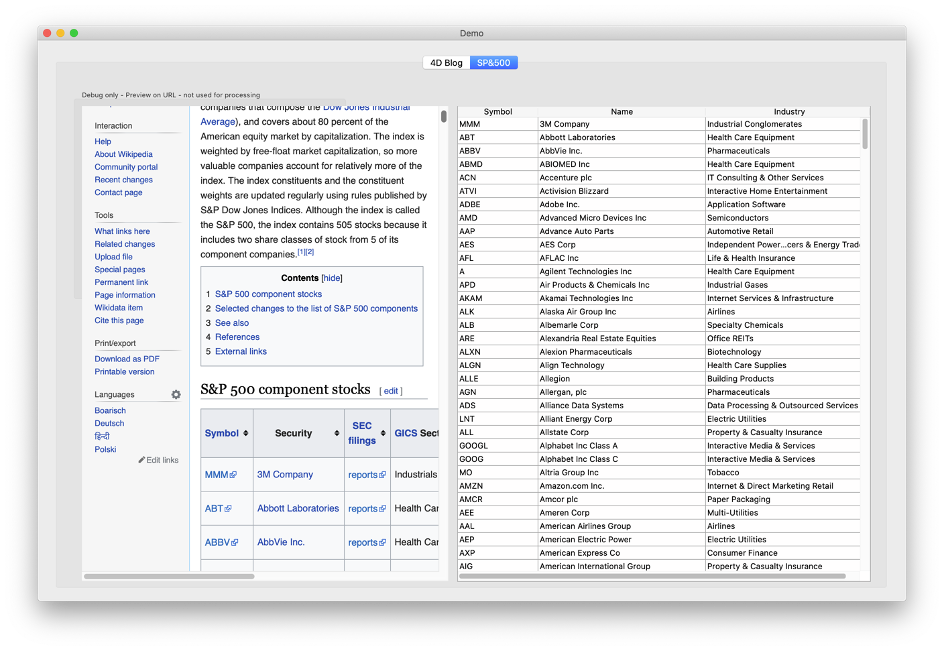
Leggete il metodo Demo_RunSP500 per analizzare il codice.
Seguiamo lo stesso schema:
Useremo un piccolo trucco per trovare il percorso dell’oggetto, perché la pagina è complessa e contiene diverse tabelle (il che rende impossibile usare un percorso normale). Qual è il trucco? Ridurre il contenuto utilizzando il primo elemento “tbody”:
$pos:=Position("<tbody>";$answertidy)
$answertidy :=Substring($answertidy;$pos)
$pos :=Position("</tbody>";$answertidy)
$answertidy :=Substring($answertidy;1;$pos+8)Poi convertiamo semplicemente il testo ridotto in un oggetto. Molto più facile!
Per trovare questa scorciatoia, apriamo la pagina con un browser e controlliamo il sorgente per trovare gli elementi che ci interessano. In questo esempio, si tratta della prima tabella. Altrimenti avremmo cercato un elemento unico, come: <table class=”wikitable sortable” id=”constituents”>.
L’elemento con il tag <tbody> è quello che ci serve. Grazie al contenuto ridotto, possiamo accedere alle righe della tabella con questo codice:
$list
Else$stocktd:=$html.tbody.tr // a collection of table rows
For each ($stock;$list)
$curstock :=New object If
($stock.th[0]#Null) // ignore the header
$curstock .symbol:=$stock.td[0].a.__value
$curstock .name:=$stock.td[1].a.__value
$curstock .industry__value
$allstocks.push($curstock)
End if
End for each
Non dimenticate di usare il debugger di 4D, che aiuta a trovare gli elementi necessari:

Se avete mai provato ad analizzare una pagina HTML usando Position/Substring o Regex, vi renderete facilmente conto dei vantaggi dell’uso delle tecniche di questo post. Se non avete mai avuto bisogno di analizzare il contenuto HTML, all’inizio potrebbe essere un po’ impegnativo, ma continuate a farlo! Si aprono nuove fonti di dati e nuovi modi per ottenere e utilizzare i dati disponibili direttamente nelle vostre applicazioni.
Avete domande, suggerimenti o volete semplicemente entrare in contatto con i blogger di 4D? Lasciateci un messaggio!
* La vostra privacy è molto importante per noi. Fare clic qui per visualizzare il nostro Politica
Al momento non è possibile lasciare commenti su questo post.