
Scraping Web à l’aide de la notation objet
avril 1, 2020
6 min de lecture

Vous souhaitez récupérer des données qui ne sont pas disponibles via REST ou des services Web ? Et si elles ne sont disponibles que sur un site web ? Les données sont assez faciles à lire pour un humain, mais lire des données HTML avec un langage de programmation n’est pas si simple. Certains développeurs essaient d’utiliser Position et Substring, d’autres essaient Regex, mais c’est désagréable et cela prend du temps. Une approche très différente consiste à convertir le HTML en objet et à obtenir les données via la notation objet. Les lignes des tableaux sont traitées comme des collections et il est facile de les parcourir en boucle !
Cet article de blog décrit comment utiliser cette approche et fournit quelques conseils pratiques.
HDI : Web Scraping en utilisant des objets
Dans notre premier exemple, nous allons commencer par la page d’accueil de notre blog : https://blog.4d.com. Disons que notre tâche consiste à analyser cette page et à afficher la liste des articles du blog dans une zone de liste avec des colonnes pour l’auteur, l’image, le titre et le contenu :
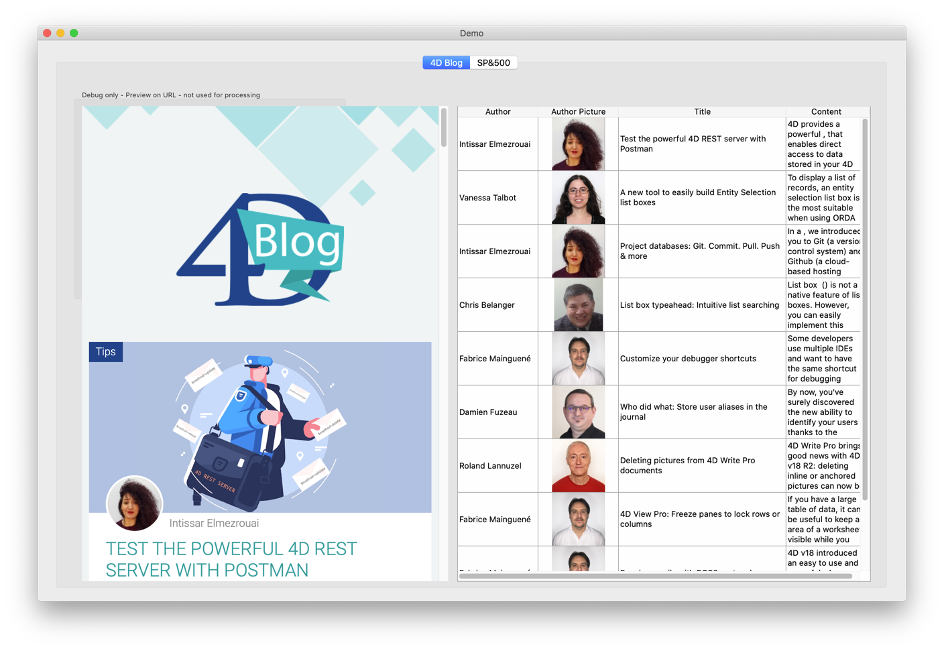
L’application de démonstration montre la page web dans une zone web à gauche pour comparer et tester (dans une application réelle, nous ne montrerions pas cela bien sûr).
Ouvrez la méthode Demo_RunBlog pour voir comment elle fonctionne. Voici les étapes importantes :
$url:= "https://blog.4d.com"
$status :=HTTP Get($url;$answer)
La première tâche consiste à charger le contenu HTML dans une variable texte. Le HTML est très tolérant ; il s’affichera correctement même s’il est truffé d’erreurs telles que des balises de fermeture manquantes(par exemple, une </p> manquante) ou des problèmes de syntaxe similaires. Cependant, cela rend l’analyse difficile puisque chaque balise d’ouverture peut ou non avoir la balise de fermeture attendue.
La bonne nouvelle est qu’il existe un outil pour corriger ce genre de problèmes, il s’appelle « tidy ». Disponible pour Mac et Windows, il peut être intégré dans une application 4D et appelé avec la commande LAUNCH EXTERNAL PROCESS.
Nous l’utilisons ici :
$answertidy:=RunTidy ($answer) // make it conform to XML
Si vous êtes curieux, vous pouvez consulter le contenu de XMLToObject si vous voulez voir comment il fonctionne, mais il n’est pas nécessaire de l’utiliser. Une fois que le contenu est dans un objet, nous pouvons utiliser la notation d’objet pour accéder directement aux éléments :
$articles:=$html.body.div[0].div.div.div[0].div.article ))
$blogposts :=New collection // collect the data
For each ($article;$articles)
$authorurl :=String($article.div[0].div[0].div.img.src)
$authorname :=String($article.div[0].div[0].span.a.__value)
$title :=String($article.div[0].span[1].a.title)
...
$blogposts .push(New object("author" ;$authorname; "picturl" ;$authorurl; "pict" ;$pict; "title" ;$title; "content" ;$content)
End for each
Bien que cela semble assez simple, la difficulté réside dans la connaissance de la position de l’objet. Dès que nous le savons, il est facile de taper la position (comme.body.div[0]…div.article).
Pour déterminer comment une page Web est construite, affichez-la dans un navigateur et ouvrez le débogueur ou l’inspecteur du navigateur Web :
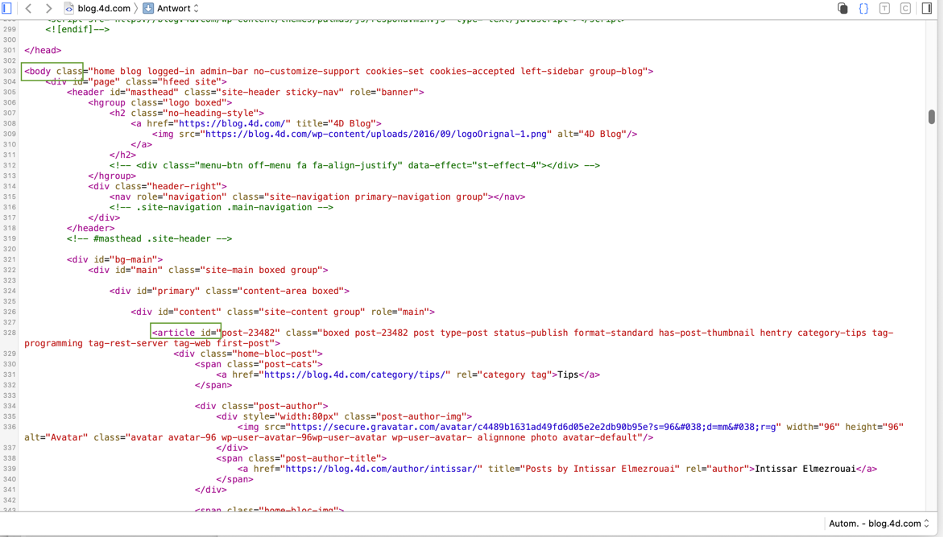
Pour cet exemple, nous devons trouver le chemin de « body » à « article« (c’est-à-dire le premier article du blog). Le débogueur fournit des indices, mais il est encore difficile de trouver le chemin. Il serait plus facile de le formater directement sous forme de liste hiérarchique. Nous allons donc suivre la méthode et placer le pointeur d’exécution sur le bloc False:
If (False) // this helps find the path in the object )
SET TEXT TO PASTEBOARD (JSON Stringify($html;*)
End if
Même dans un éditeur de texte, le texte est difficile à lire, mais des outils tels que VisualJSON ou Notepad++ (avec l’extension JSONViewer) aident beaucoup ! Voici à quoi cela ressemble dans VisualJSON :
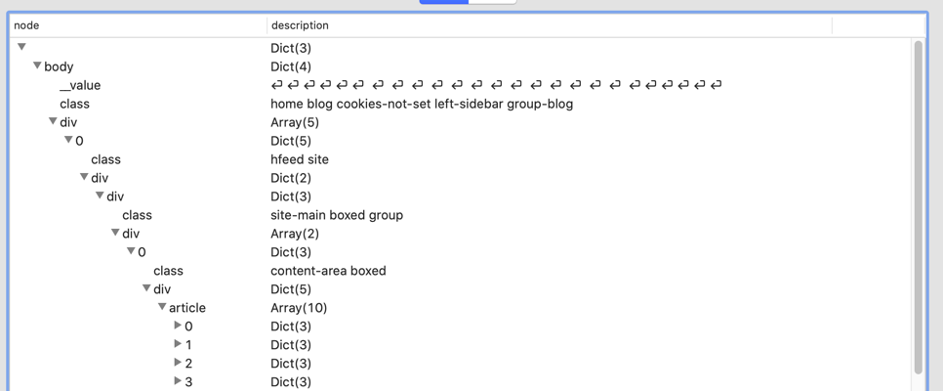
Ceci montre le chemin vers body.div[0].div.div.div[0].div.article.
Le débogueur de 4D fournit une liste similaire :
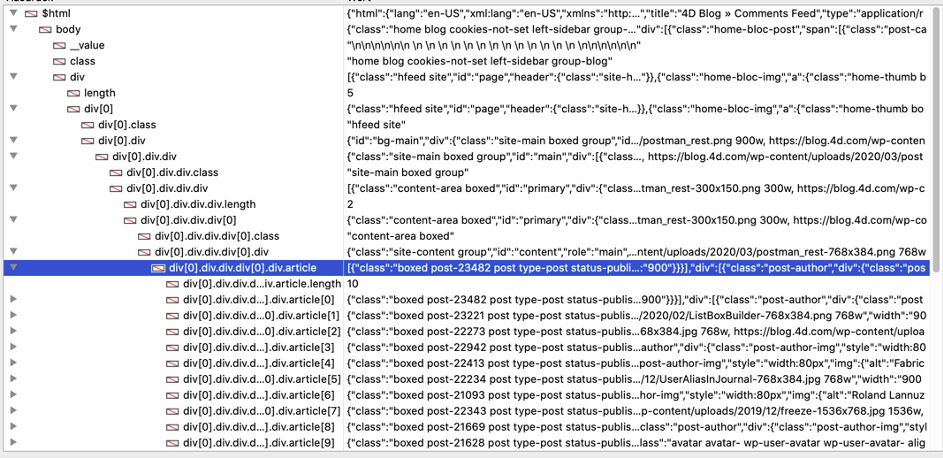
« Article » est une collection et chaque élément contient un seul article de blog. Nous pouvons parcourir la collection en boucle avec For Each et accéder aux champs requis.« image » est une image HTML standard et src contient l’URL, nousobtenons doncl’URL et utilisons HTTP Get pour télécharger l’image. Enfin, la méthode construit et ajuste la boîte de liste pour afficher les données.
Dans notre deuxième exemple, nous récupérons les données d’un tableau sur Wikipédia :
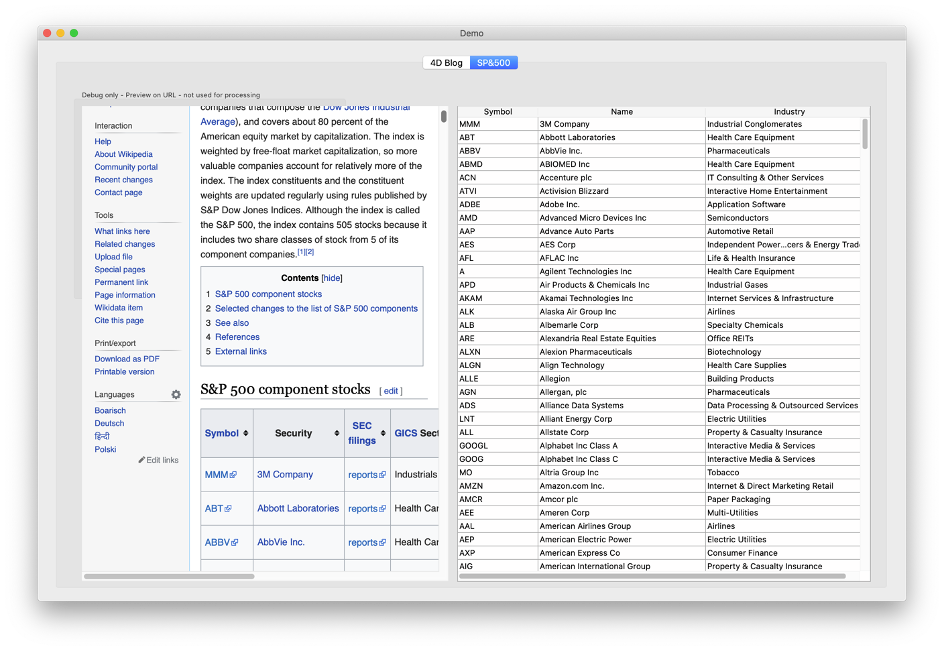
Lisez la méthode Demo_RunSP500 pour analyser le code.
Nous suivons le même schéma :
Nous allons utiliser une petite astuce pour trouver le chemin de l’objet, car la page est complexe et contient plusieurs tableaux (ce qui rend impossible l’utilisation d’un chemin normal). Quelle est l’astuce ? Réduisez le contenu en utilisant le premier élément « tbody » :
$pos:=Position("<tbody>" ;$answertidy)
$answertidy :=Substring($answertidy;$pos)
$pos :=Position("</tbody>" ;$answertidy)
$answertidy :=Substring($answertidy;1 ;$pos+8)Ensuite, nous convertissons simplement le texte réduit en objet. Beaucoup plus facile !
Pour trouver ce raccourci, nous ouvrons la page avec un navigateur et vérifions la source pour trouver les éléments qui nous intéressent vraiment. Dans cet exemple, il s’agit du premier tableau. Sinon, nous aurions cherché un élément unique, tel que : <table class= »wikitable sortable » id= »constituents »>.
L’élément avec la balise <tbody> est celui dont nous avons besoin. Grâce au contenu réduit, nous pouvons accéder aux lignes du tableau avec ce code :
$list$stocktd:=$html.tbody.tr // a collection of table rows
For each ($stock;$list)
$curstock :=New object
If
($stock.th[0]#Null) // ignore the header
Else
$curstock .symbol:=$stock.td[0].a.__value
$curstock .name:=$stock.td[1].a.__value
$curstock .industry__value
$allstocks.push($curstock)
End if
End for each
N’oubliez pas d’utiliser le débogueur de 4D, qui aide également à trouver les éléments nécessaires :

Si vous avez déjà essayé d’analyser une page HTML en utilisant Position/Substring ou Regex, vous verrez facilement les avantages de l’utilisation des techniques présentées dans ce billet. Si vous n’avez jamais eu besoin d’analyser du contenu HTML, cela peut être un peu difficile au début, mais persévérez ! Cela ouvre de nouvelles sources de données et de nouvelles façons d’obtenir et d’utiliser les données disponibles directement dans vos applications.
Vous avez une question, une suggestion ou vous voulez simplement entrer en contact avec les blogueurs 4D ? Envoyez-nous un message !
* Votre vie privée est très importante pour nous. Veuillez cliquer ici pour consulter notre Politique
Les commentaires ne sont pas disponibles pour cet article pour le moment.