
Škrabání webu pomocí objektové notace
1 dubna, 2020
6 Čas na přečtení

Chcete získat data, která nejsou dostupná prostřednictvím REST nebo webových služeb? Co když jsou k dispozici pouze na webových stránkách? Člověk si data přečte dostatečně snadno, ale čtení dat HTML pomocí programovacího jazyka už tak jednoduché není. Někteří vývojáři se pokoušejí používat funkce Position a Substring, jiní zkoušejí Regex, ale je to nepříjemné a časově náročné. Zcela odlišný přístup spočívá v převedení jazyka HTML na objekt a získání dat pomocí objektového zápisu. Řádky tabulky se zpracovávají jako kolekce a lze je snadno procházet ve smyčce!
Tento příspěvek na blogu popisuje, jak tento přístup použít, a poskytuje několik užitečných tipů.
HDI: Škrabání webu pomocí objektů
V našem prvním příkladu začneme domovskou stránkou našeho blogu: https: //private-blog.4d.com. Řekněme, že naším úkolem je analyzovat tuto stránku a zobrazit seznam příspěvků blogu v poli se seznamem se sloupci pro autora, obrázek, název a obsah:
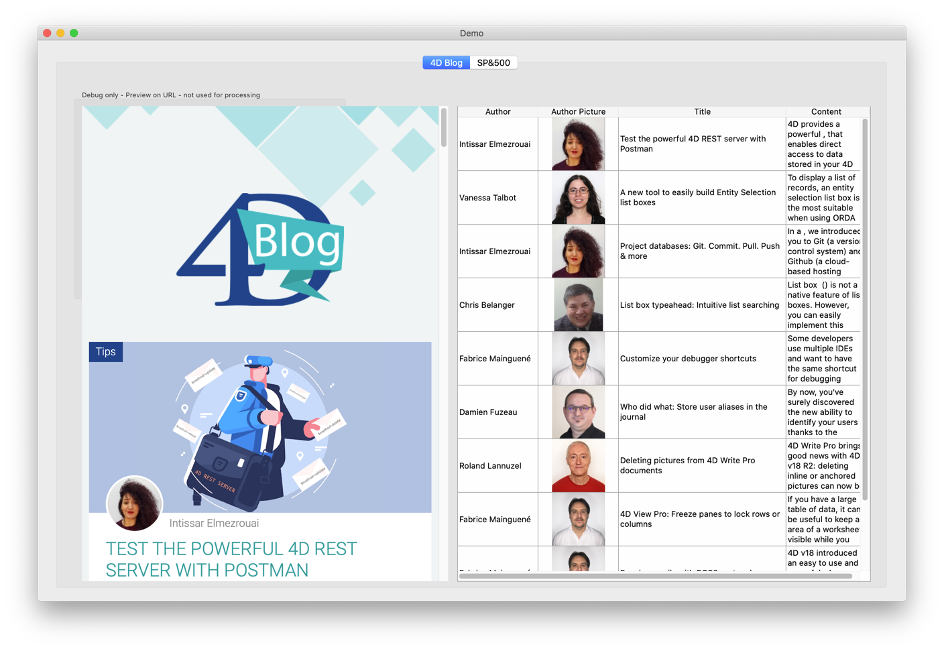
Demonstrační aplikace zobrazuje webovou stránku ve webové oblasti vlevo pro porovnání a testování (ve skutečné aplikaci bychom to samozřejmě nezobrazovali).
Otevřete si metodu Demo_RunBlog a podívejte se, jak funguje. Zde jsou uvedeny důležité kroky:
$url:="https://blog.4d.com"
$status :=HTTP Get($url;$answer)
Prvním úkolem je načíst obsah HTML do textové proměnné. Jazyk HTML je velmi tolerantní; zobrazí se správně, i když je plný chyb, jako jsou chybějící uzavírací značky(např. , chybějící </p>) nebo podobné syntaktické problémy. To však ztěžuje analýzu, protože každá otevírací značka může, ale nemusí mít očekávanou uzavírací značku.
Dobrou zprávou je, že existuje nástroj pro opravu takovýchto problémů, jmenuje se „tidy„. Je k dispozici pro Mac i Windows, lze jej vložit do aplikace 4D a vyvolat příkazem LAUNCH EXTERNAL PROCESS.
My jej používáme zde:
$answertidy:=RunTidy ($answer) // make it conform to XML
Pokud jste zvědaví, můžete se podívat na obsah příkazu XMLToObject, pokud chcete vidět, jak funguje, ale není nutné ho používat. Jakmile je obsah v objektu, můžeme použít objektový zápis pro přímý přístup k prvkům:
$articles:=$html.body.div[0] .div.div.div[0].div.article )
$blogposts :=New collection // collect the data
For each ($article;$articles)
$authorurl :=String($article.div[0].div[0].div.img.src)
$authorname :=String($article.div[0].div[0].span.a.__value)
$title :=String($article.div[0].span[1].a.title)
...
$blogposts .push(New object("author";$authorname; "picturl";$authorurl; "pict";$pict; "title";$title; "content";$content)
End for each
I když to vypadá docela jednoduše, problém spočívá ve znalosti polohy objektu. Jakmile ji známe, je zadání pozice (například.body.div[0]…div.article) snadné.
Chcete-li zjistit, jak je webová stránka sestavena, zobrazte ji v prohlížeči a otevřete ladicí program nebo inspektor webového prohlížeče:
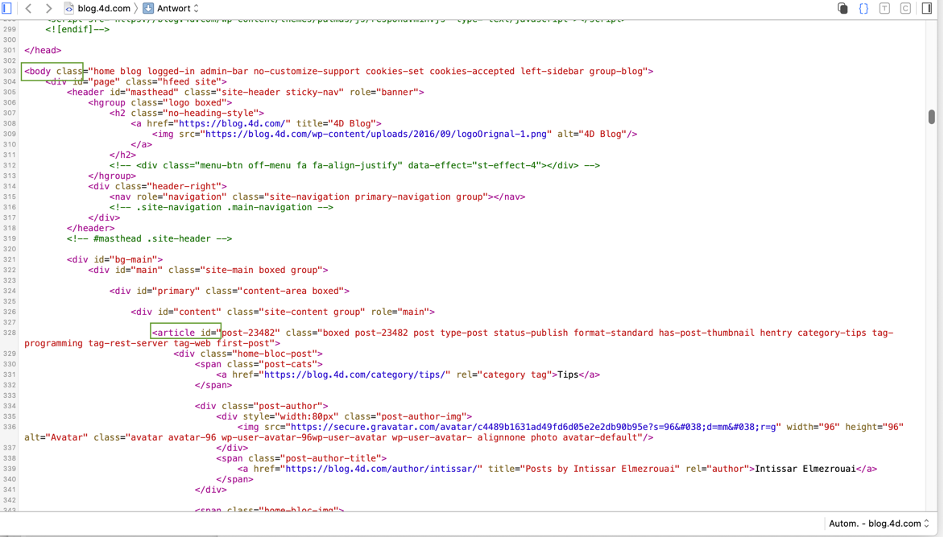
Pro tento příklad potřebujeme zjistit cestu od „body“ k „article“ (tj. , prvnímu článku blogu). Ladicí program poskytuje vodítka, ale najít cestu je stále obtížné. Bylo by jednodušší, kdybychom ji mohli formátovat přímo jako hierarchický seznam, takže budeme sledovat metodu a nastavíme ukazatel provádění na blok False:
If (False) // this helps find the path in the object
SET TEXT TO PASTEBOARD (JSON Stringify($html;*))
End if
I v textovém editoru je text obtížně čitelný, ale nástroje jako VisualJSON nebo Notepad++ (s rozšířením JSONViewer) nám v tom velmi pomáhají! Tady je vidět, jak to vypadá ve VisualJSON:
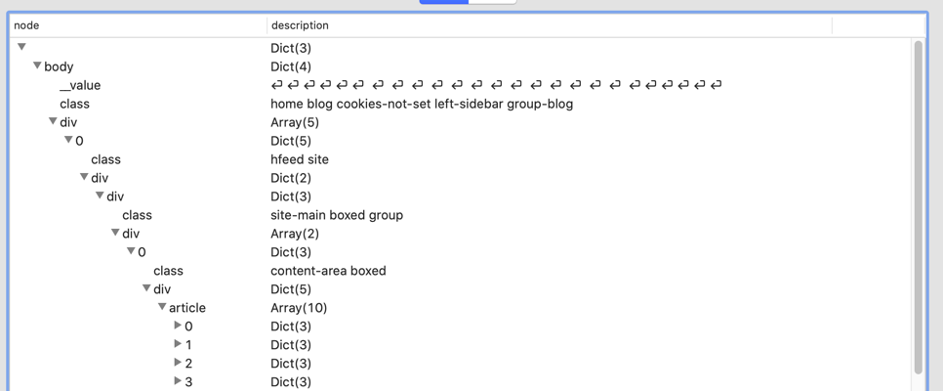
Tohle ukazuje cestu k body.div[0].div.div.div[0].div.article.
Podobný seznam poskytuje i ladicí program 4D:
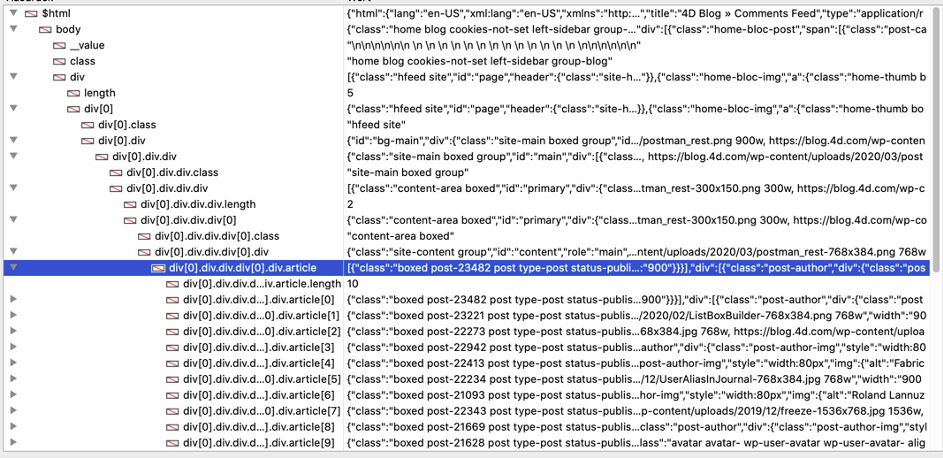
„Article“ je kolekce a každý prvek obsahuje jeden příspěvek na blogu. Kolekci můžeme procházet pomocí For Each a přistupovat k požadovaným polím.„image“ je standardní HTML obrázek a src obsahuje URL, takžezískáme URL a pomocí HTTP Get stáhneme obrázek. Nakonec metoda sestaví a upraví pole seznamu tak, aby zobrazovalo data.
V našem druhém příkladu získáváme data z tabulky na Wikipedii:
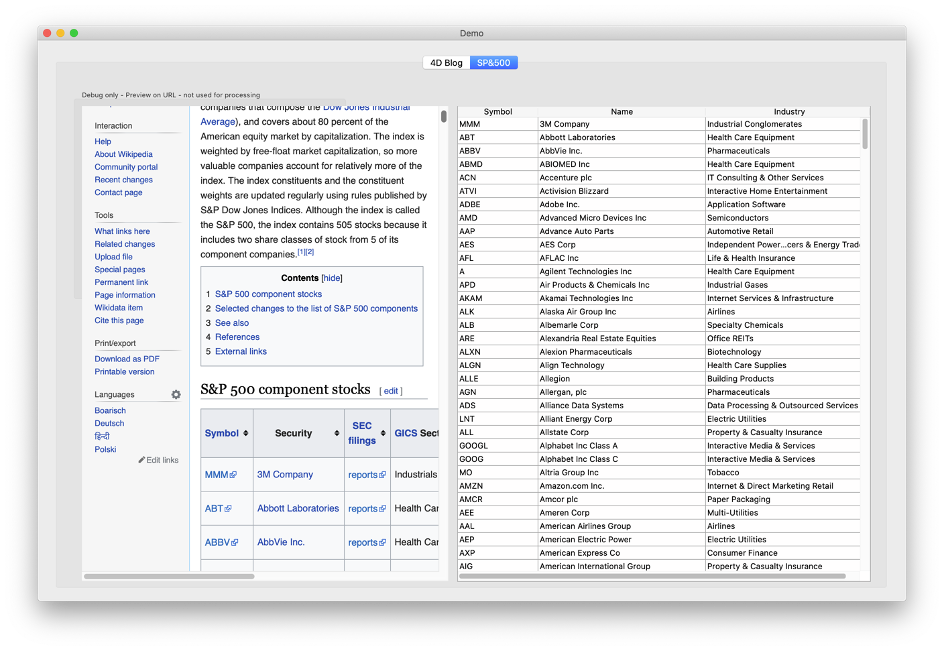
Přečtěte si metodu Demo_RunSP500 a analyzujte kód.
Postupujeme podle stejného vzoru:
K nalezení cesty k objektu použijeme malý trik, protože stránka je složitá a obsahuje několik tabulek (což znemožňuje použití běžné cesty). Jaký je tedy trik? Zredukujte obsah pomocí prvního elementu „tbody“:
$pos:=Position("<tbody>";$answertidy)
$answertidy :=Substring($answertidy;$pos)
$pos :=Position("</tbody>";$answertidy)
$answertidy :=Substring($answertidy;1;$pos+8)Pak jednoduše převedeme redukovaný text na objekt. Mnohem jednodušší!
Abychom tuto zkratku našli, otevřeme stránku pomocí prohlížeče a zkontrolujeme zdrojový kód, abychom našli prvky, které nás skutečně zajímají. V tomto příkladu je to první tabulka. Jinak bychom hledali jedinečný prvek, například: <table class=“wikitable sortable“ id=“constituents“>.
Potřebujeme tedy element s tagem <tbody>. Díky redukovanému obsahu můžeme pomocí tohoto kódu přistupovat k řádkům tabulky:
$list$stocktd:=$html.tbody.tr // a collection of table rows
For each ($stock;$list)
$curstock :=New object
If
($stock.th[0]#Null) // ignore the header
Else
$curstock .symbol:=$stock.td[0].a.__value
$curstock .name:=$stock.td[1].a.__value
$curstock .industry__value
$allstocks.push($curstock)
End if
End for each
Nezapomeňte použít ladicí program 4D, který rovněž pomáhá najít požadované prvky:

Pokud jste se někdy pokoušeli analyzovat stránku HTML pomocí Position/Substring nebo Regex, snadno poznáte výhody použití technik uvedených v tomto příspěvku. Pokud jste nikdy nepotřebovali analyzovat obsah HTML, může to být zpočátku ještě trochu náročné, ale vydržte! Otevře vám to nové zdroje dat a nové způsoby, jak získávat a používat dostupná data přímo ve vašich aplikacích.
Máte dotaz, návrh nebo se chcete spojit s blogery 4D? Napište nám!
* Vaše soukromí je pro nás velmi důležité. Kliknutím sem si můžete prohlédnout naše Zásady
K tomuto příspěvku zatím nelze přidávat komentáře.