
オブジェクト記法によるWebスクレイピング
4月 1, 2020
2 読了時間

RESTやWebサービスでは利用できないデータを取得したい?Webサイトにしかないデータならどうでしょう?人間が読むには簡単なデータですが、プログラミング言語でHTMLデータを読むのはそう簡単ではありません。ある開発者はPositionやSubstringを使おうとし、またある開発者はRegexを使おうとしますが、不快で時間がかかるものです。全く異なるアプローチは、HTMLをオブジェクトに変換し、オブジェクト記法でデータを取得することです。テーブルの行はコレクションとして扱われるため、ループ処理を行うのが簡単です!
このブログ記事では、このアプローチの使用方法と、いくつかの便利なヒントを紹介しています。
最初の例では、ブログのホームページから始めます。https://blog.4d.com。私たちのタスクは、このページを解析して、著者、画像、タイトル、内容のカラムを持つリストボックスにブログの投稿のリストを表示することだとします。
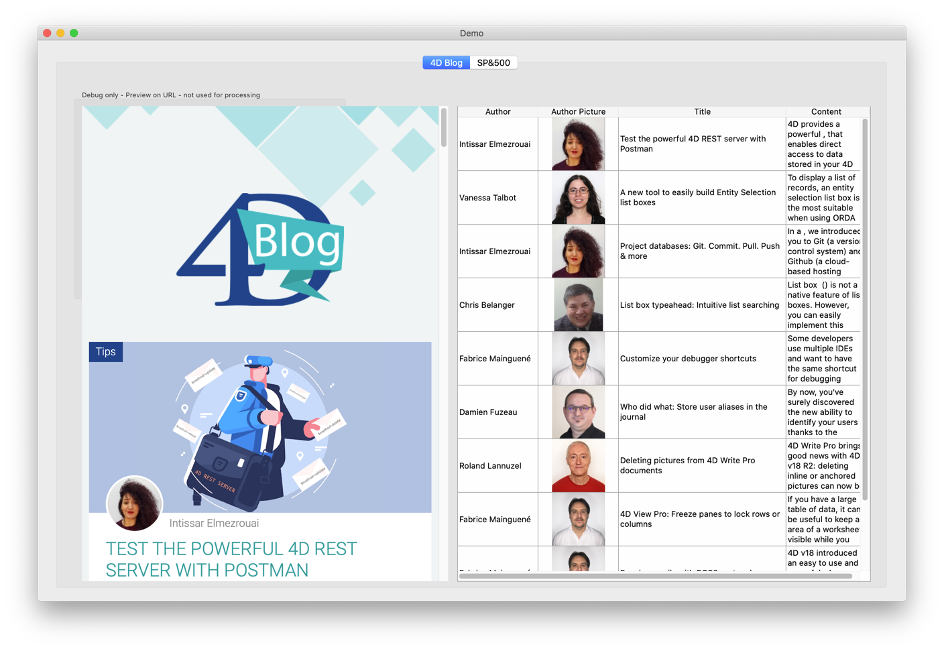
デモアプリケーションでは、比較とテストのために左側のウェブ領域にウェブページを表示しています(実際のアプリケーションでは、もちろん表示しません)。
どのように動作するかを見るためにDemo_RunBlog メソッドを開いてください。以下は、重要なステップです。
$url:="https://blog.4d.com"
$status :=HTTP Get($url;$answer)
最初の作業は、HTMLの内容をテキスト変数に読み込むことです。HTMLは非常に寛容で、閉じタグの欠落(例:</p>の欠落)や同様の構文問題などのエラーに満ちていても、正しく表示されます。しかし、すべての開始タグが期待される終了タグを持っていたりいなかったりするため、分析が困難です。
このような問題を修正するツールは、「tidy」と呼ばれています。MacとWindowsの両方で利用でき、4Dアプリケーションに埋め込んで、LAUNCH EXTERNAL PROCESS コマンドで呼び出すことができます。
ここでは、それを使っています。
$answertidy:=RunTidy ($answer)// make it conform to XML
もし、興味があれば、 XMLToObject の内容を確認することができますが、使用する必要はありません。内容がオブジェクトになれば、オブジェクト記法で直接要素にアクセスできるようになります。
$articles:=$html.body.div[0].div.div.div $authorname[div.article )
$blogposts :=New collection // collect the data
For each ($article;$articles)
$authorurl :=String($article.div[0].div[0].div.imgsrc )
:=String($article.div[0].div[0].span.a.__value)
$title :=String($article.div[0].span[1].a.title)
...
$blogposts .push(New object("author";$authorname; "picturl";$authorurl; "pict";$pict; "title";$title; "content";$content)
End for each
一見簡単そうに見えますが、オブジェクトの位置が分かることが課題です。これがわかれば、位置をタイプするのは簡単です(たとえば、.body.div[0]…div.articleのように)。
Web ページがどのように作られているかを知るには、そのページをブラウザで表示し、Web ブラウザのデバッガやインスペクタを開いてください。
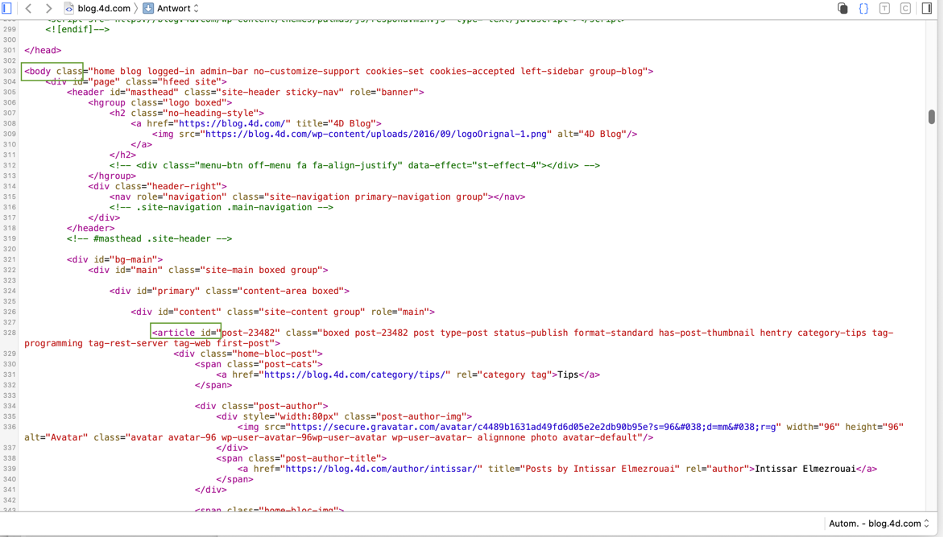
この例では、「body」から「article」(つまり、最初のブログ記事)までのパスを見つける必要があります。デバッガーは手がかりを与えてくれますが、パスを見つけるのはまだ困難です。階層的なリストとして直接フォーマットできれば簡単なので、メソッドをトレースして実行ポインタをFalse ブロックにセットしてみましょう。
If ( ) ( ( ;*))False // this helps find the path in the object
SET TEXT TO PASTEBOARDJSON Stringify$html
End if
テキストエディタでも読みにくいですが、VisualJSONやNotepad++(JSONViewerの拡張機能付き)などのツールを使うと、かなり楽になりますよ。VisualJSONで見るとこんな感じです。
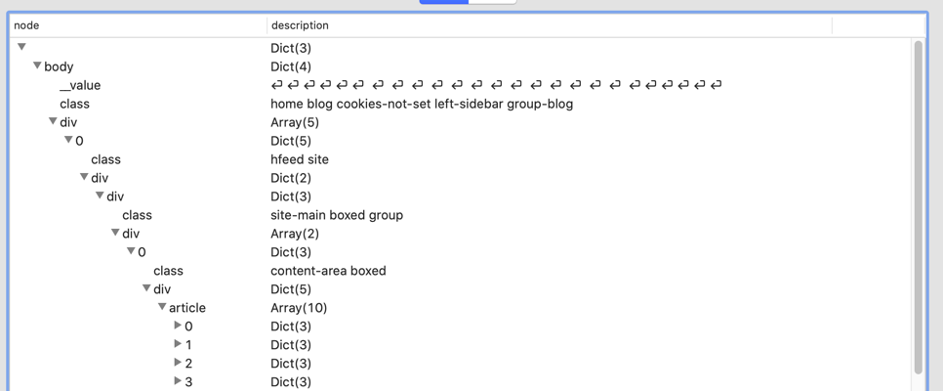
これは、body.div[0].div.div[0].div.articleへのパスを示しています。
4Dのデバッガでも同様のリストが表示されます。
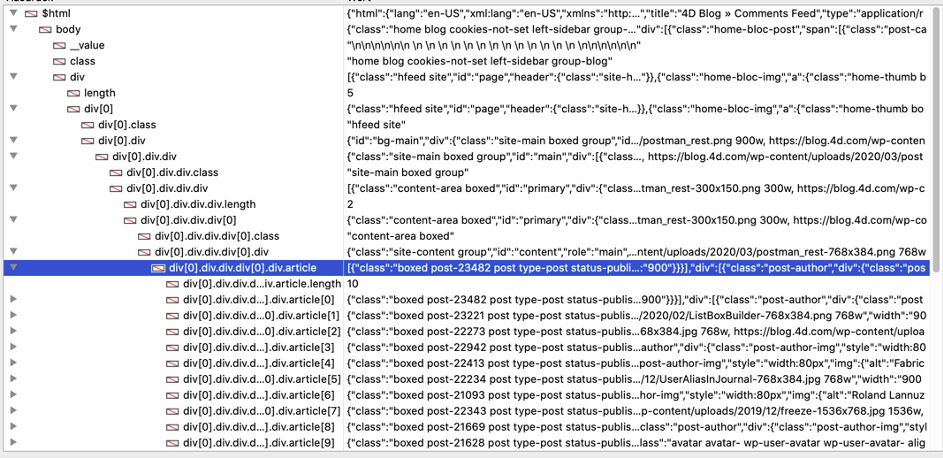
“Article “はコレクションで、各要素には1つのブログ投稿が含まれています。 For Each でコレクションをループして、必要なフィールドにアクセスすることができます。”image “は標準的なHTML画像で、srcにはURLが含まれているので、URLを取得し、HTTP Get 、画像をダウンロードするために使用します。最後に、このメソッドはリストボックスを構築し、データを表示するように調整します。
2番目の例では、Wikipediaのテーブルからデータを取得します。
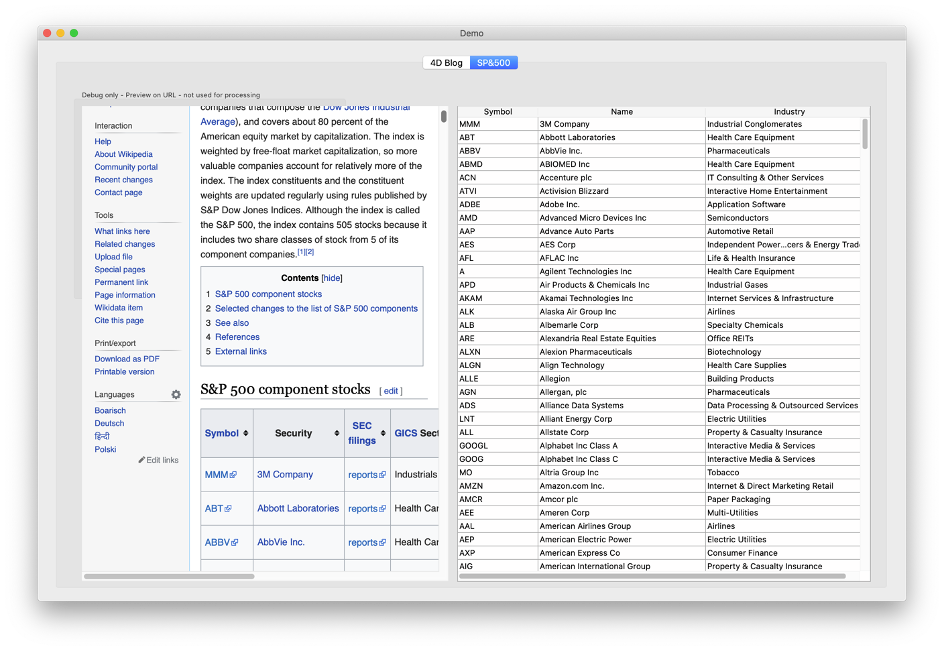
Demo_RunSP500 メソッドを読んで、コードを解析してみましょう。
同じパターンをたどります。
このページは複雑で、いくつかのテーブルが含まれているため、オブジェクトのパスを見つけるためにちょっとしたトリックを使用します(通常のパスを使用することは不可能です)。そのトリックとは?最初の「tbody」要素を使って、内容を縮小します。
$pos:=Position("<tbody>";$answertidy)
$answertidy :=Substring($answertidy;$pos)
$pos :=Position("</tbody>";$answertidy)
$answertidy :=Substring($answertidy;1;$pos+8)あとは、縮小テキストをオブジェクトに変換すればいいのです。とても簡単ですね。
このショートカットを見つけるには、ブラウザでページを開いてソースをチェックし、本当に関心のある要素を見つけます。この例では、最初のテーブルがそれです。そうでなければ、次のようなユニークな要素を探したでしょう:<table class=”wikitable sortable” id=”constructents”>。
<tbody>タグのある要素が、私たちが必要としているものです。縮小されたコンテンツのおかげで、このコードでテーブルの行にアクセスすることができます。
$list Elsesymbol$stocktd:=$html.tbody.tr// a collection of table rows
For each ($stock;$list)
$curstock :=New object
If
($stock.th[0]#Null)// ignore the header
$curstock :=$stock.td[0].a.__value
$curstock name :=$stock.td[1].a.__value
$curstock .industry 。__value
$allstockspush ($curstock)
End if
End for each
4D のデバッガーを使うことを忘れないでください。これも必要な要素を見つけるのに役立ちます。

Position/SubstringやRegexを使ってHTMLページを解析しようとしたことがあれば、このブログ記事のテクニックを使うことの利点が簡単にわかるでしょう。HTMLコンテンツを解析する必要がない場合、最初は少し難しいかもしれませんが、粘り強く取り組んでください。新しいデータソースと、利用可能なデータをアプリケーションで直接取得し使用する新しい方法を開くことができます。
現在、この投稿へのコメント機能は利用できません。