
Raspado de la web utilizando la notación de objetos
abril 1, 2020
6 tiempo de lectura

¿Quiere recuperar datos que no están disponibles a través de REST o servicios web? ¿Y si sólo están disponibles en un sitio web? Los datos son bastante fáciles de leer para un humano, pero leer datos HTML con un lenguaje de programación no es tan sencillo. Algunos desarrolladores intentan utilizar Position y Substring, otros prueban con Regex, pero es desagradable y lleva mucho tiempo. Un enfoque muy diferente es convertir el HTML en un objeto y obtener los datos mediante la notación de objetos. Las filas de la tabla se manejan como colecciones y son fáciles de recorrer.
Esta entrada del blog describe cómo utilizar este enfoque y proporciona algunos consejos útiles.
HDI: Web Scraping usando objetos
En nuestro primer ejemplo, comenzaremos con la página principal de nuestro blog: https://blog.4d.com. Digamos que nuestra tarea es analizar esta página y mostrar la lista de entradas del blog en un cuadro de lista con columnas para el autor, la imagen, el título y el contenido:
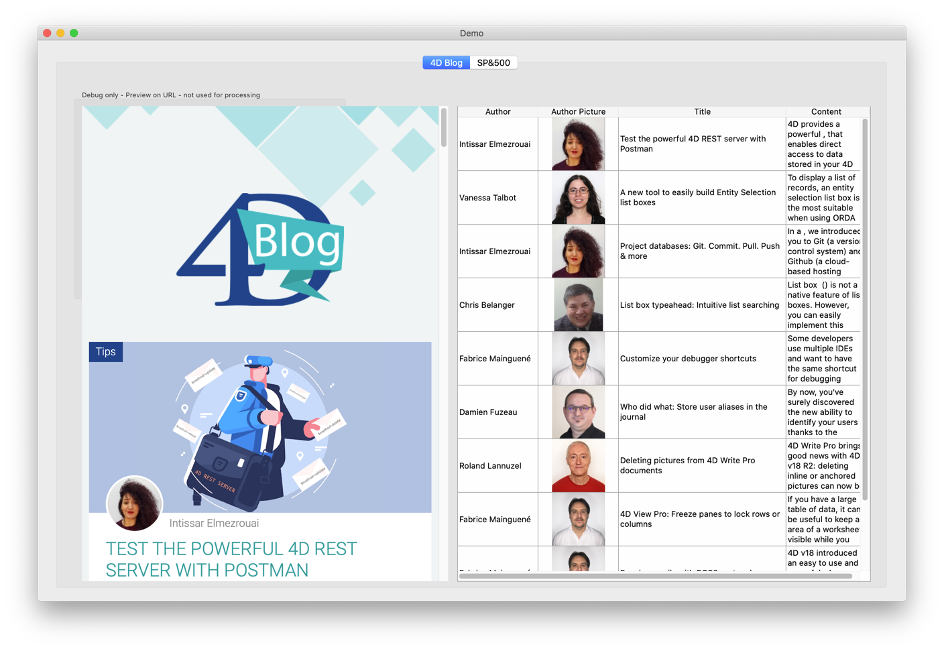
La aplicación de demostración muestra la página web en un área web a la izquierda para comparar y probar (en una aplicación real no mostraríamos eso, por supuesto).
Abra el método Demo_RunBlog para ver cómo funciona. Aquí están los pasos importantes:
$url:="https://blog.4d.com"
$status :=HTTP Get($url;$answer)
La primera tarea es cargar el contenido HTML en una variable de texto. El HTML es muy tolerante; se mostrará correctamente aunque esté lleno de errores, como la falta de etiquetas de cierre (porejemplo, la falta de </p>) o problemas de sintaxis similares. Sin embargo, esto dificulta el análisis, ya que cada etiqueta de apertura puede tener o no la etiqueta de cierre esperada.
La buena noticia es que existe una herramienta para corregir problemas como éste, se llama «tidy». Disponible tanto para Mac como para Windows, se puede incrustar en una aplicación 4D y llamarla con el comando LAUNCH EXTERNAL PROCESS.
Lo usamos aquí:
$answertidy:=RunTidy ($answer) // make it conform to XML
Si tienes curiosidad, puedes consultar el contenido de XMLToObject si quieres ver cómo funciona, pero no es necesario utilizarlo. Una vez que el contenido está en un objeto, podemos utilizar la notación de objetos para acceder directamente a los elementos:
$articles:=$html.body.div[0].div.div.div[0].div.article )
$blogposts :=New collection // collect the data
For each ($article;$articles)
$authorurl :=String($article.div[0].div[0].div.img.src)
$authorname :=String($article.div[0].div[0].span.a.__value)
$title :=String($article.div[0].span[1].a.title)
...
$blogposts .push(New object("autor";$authorname; "picturl";$authorurl; "pict";$pict; "título";$title; "contenido";$content)
End for each
Aunque parece bastante sencillo, el reto está en conocer la posición del objeto. En cuanto lo sepamos, escribir la posición (como.body.div[0]…div.article) es fácil.
Para determinar cómo está construida una página web, visualízala en un navegador y abre el depurador o inspector del navegador:
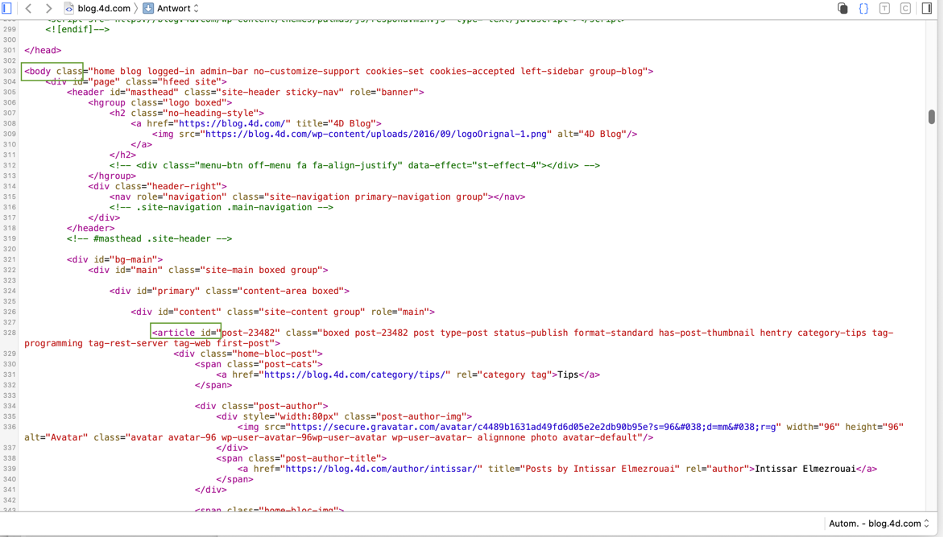
Para este ejemplo, necesitamos encontrar la ruta desde «body» hasta «article«(es decir, el primer artículo del blog). El depurador proporciona pistas, pero encontrar la ruta sigue siendo difícil. Sería más fácil si pudiéramos formatearla directamente como una lista jerárquica, así que rastrearemos el método y pondremos el puntero de ejecución en el bloque False:
If (False) // this helps find the path in the object
SET TEXT TO PASTEBOARD (JSON Stringify($html;*))
End if
Incluso en un editor de texto, el texto es difícil de leer, pero herramientas como VisualJSON o Notepad++ (con la extensión JSONViewer) ayudan mucho. Así es como se ve en VisualJSON:
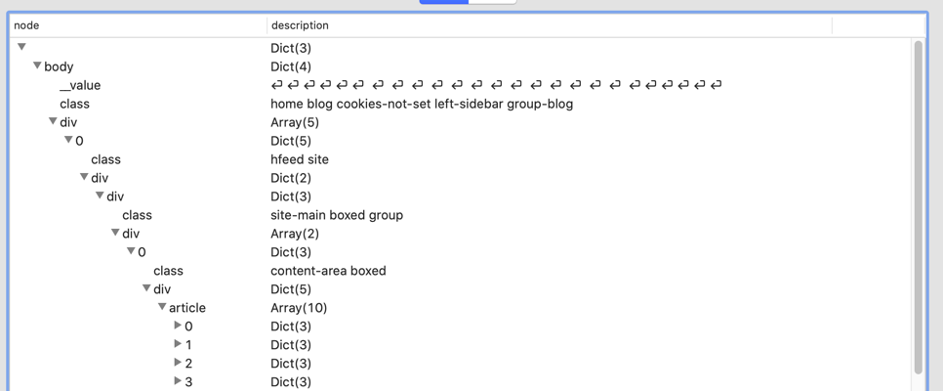
Esto muestra la ruta a body.div[0].div.div[0].div.article.
El depurador de 4D proporciona una lista similar:
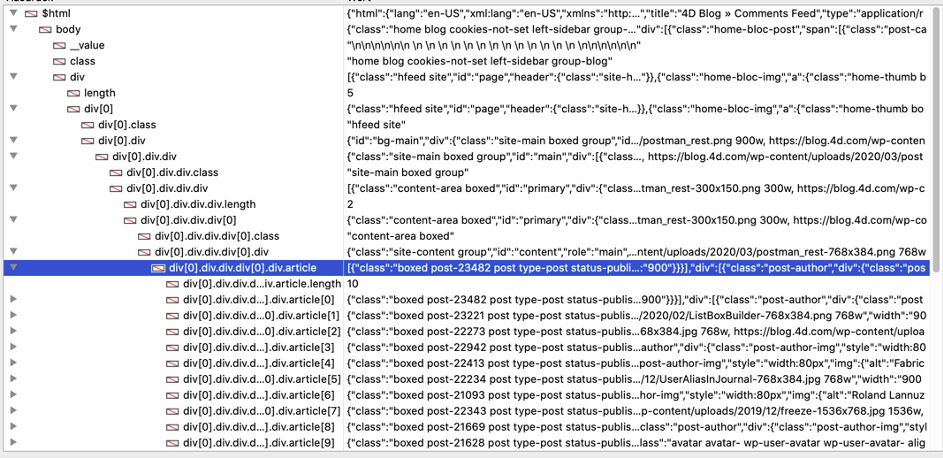
«Article » es una colección y cada elemento contiene una sola entrada del blog. Podemos recorrer la colección con For Each y acceder a los campos necesarios. «image » es una imagen HTML estándar y src contiene la URL, así queobtenemos la URL y usamos HTTP Get para descargar la imagen. Finalmente, el método construye y ajusta el cuadro de lista para mostrar los datos.
En nuestro segundo ejemplo, recuperamos datos de una tabla de Wikipedia:
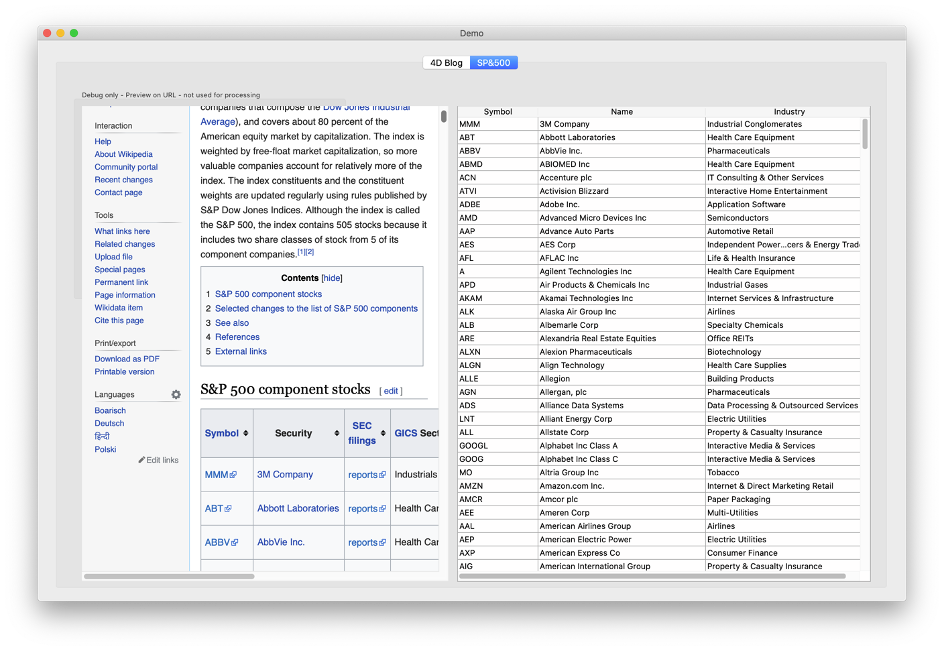
Lee el método Demo_RunSP500 para analizar el código.
Seguimos el mismo patrón:
Usaremos un pequeño truco para encontrar la ruta del objeto, porque la página es compleja y contiene varias tablas (lo que hace imposible usar una ruta normal). ¿Cuál es el truco? Reducir el contenido utilizando el primer elemento «tbody»:
$pos:=Position("<tbody>";$answertidy)
$answertidy :=Substring($answertidy;$pos)
$pos :=Position("</tbody>";$answertidy)
$answertidy :=Substring($answertidy;1;$pos+8)Luego simplemente convertimos el texto reducido en un objeto. ¡Mucho más fácil!
Para encontrar este atajo, abrimos la página con un navegador y revisamos la fuente para encontrar los elementos que realmente nos interesan. En este ejemplo, es la primera tabla. Si no, habríamos buscado un elemento único, como: <table class=»wikitable sortable» id=»constituents»>.
El elemento con la etiqueta <tbody> es el que necesitamos. Gracias al contenido reducido, podemos acceder a las filas de la tabla con este código:
$list$stocktd:=$html.tbody.tr // a collection of table rows
For each ($stock;$list)
$curstock :=New object
If
($stock.th[0]#Null) // ignore the header
Else
$curstock .symbol:=$stock.td[0].a.__value
$curstock .name:=$stock.td[1].a.__value
$curstock .industry__value
$allstocks.push($curstock)
End if
End for each
No olvide utilizar el depurador de 4D, que también ayuda a encontrar los elementos necesarios:

Si alguna vez ha tratado de parsear una página HTML usando Position/Substring o Regex, verá fácilmente los beneficios de usar las técnicas de esta entrada del blog. Si nunca has necesitado analizar contenido HTML, puede ser un poco difícil al principio, pero ¡sigue con ello! Abre nuevas fuentes de datos y nuevas formas de obtener y utilizar los datos disponibles directamente en tus aplicaciones.
¿Tiene alguna pregunta, sugerencia o simplemente quiere ponerse en contacto con los bloggers de 4D? Escríbenos.
* Su privacidad es muy importante para nosotros. Haga clic aquí para ver nuestra Política
Por el momento, no se pueden publicar comentarios en esta entrada.