
Web Scraping using object notation
April 1, 2020
5 min read

Want to retrieve data that isn’t available via REST or Web Services? What if it’s only available on a website? The data is easy enough for a human to read, but reading HTML data with a programming language isn’t so simple. Some developers try to use Position and Substring, others try Regex, but it’s unpleasant and time-consuming. A very different approach is to convert the HTML into an object and get the data via object notation. Table rows are handled as collections and are easy to loop through!
This blog post describes how to use this approach and provides some handy tips.
HDI: Web Scraping using objects
In our first example, we’ll start with our blog’s homepage: https://blog.4d.com. Let’s say our task is to parse this page and display the list of blog posts in a list box with columns for author, picture, title, and content:
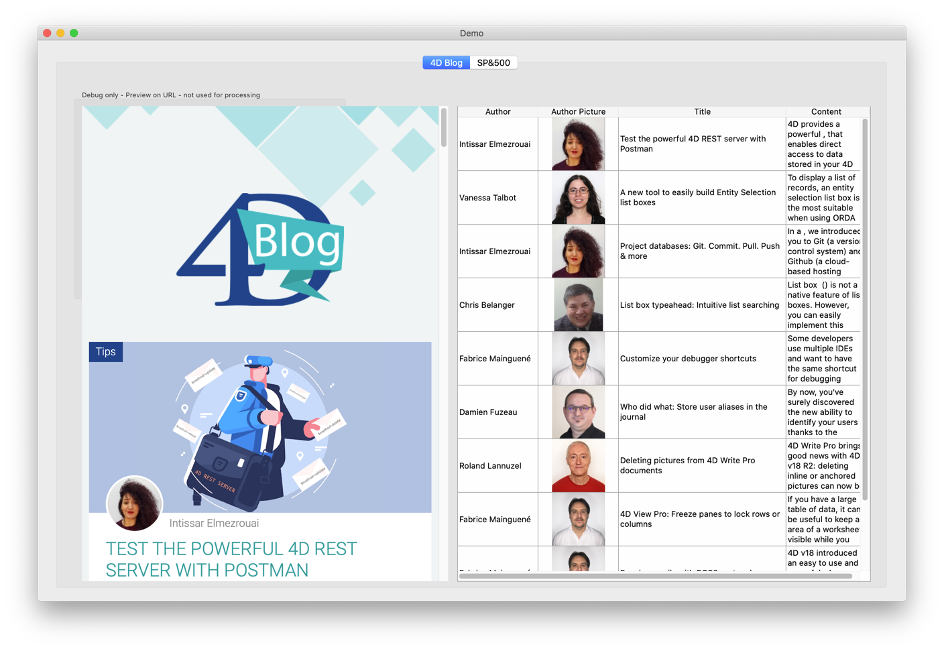
The demo application shows the web page in a web area on the left to compare and test (in a real application we wouldn’t show that of course).
Open the Demo_RunBlog method to see how it works. Here are the important steps:
$url:="https://blog.4d.com"
$status:=HTTP Get($url;$answer)
The first task is to load the HTML content into a text variable. HTML is very tolerant; it’ll still be displayed correctly even if it’s full of errors such as missing closing tags (e.g., a missing </p>) or similar syntax issues. However, this makes it difficult to analyze since every opening tag may or may not have the expected closing tag.
The good news is that there’s a tool to correct problems like this, it’s called “tidy”. Available for both Mac and Windows, it can be embedded in a 4D application and called with the LAUNCH EXTERNAL PROCESS command.
We’re using it here:
$answertidy:=RunTidy ($answer) // make it conform to XML
If you’re curious, you can check the content of XMLToObject if you want to see how it works, but it’s not necessary to use it. Once the content is in an object, we can use object notation to directly access elements:
$articles:=$html.body.div[0].div.div.div[0].div.article
$blogposts:=New collection // collect the data
For each ($article;$articles)
$authorurl:=String($article.div[0].div[0].div.img.src)
$authorname:=String($article.div[0].div[0].span.a.__value)
$title:=String($article.div[0].span[1].a.title)
…
$blogposts.push(New object("author";$authorname;"picturl";$authorurl;"pict";$pict;"title";$title;"content";$content))
End for each
While it looks pretty simple, the challenge lies in knowing the position of the object. As soon as we know this, typing the position (such as .body.div[0]…div.article) is easy.
To determine how a web page is built, display it in a browser and open the web browser’s debugger or inspector:
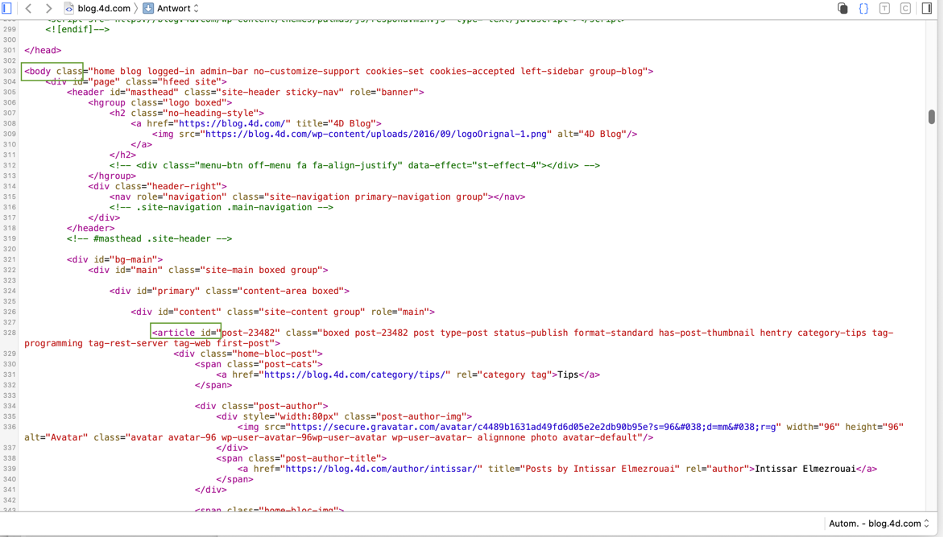
For this example, we need to find the path from “body” to “article” (i.e., the first blog article). The debugger provides clues, but finding the path is still difficult. It’d be easier if we could format it directly as a hierarchical list, so we’ll trace through the method and set the execution pointer to the False block:
If (False) // this helps find the path in the object
SET TEXT TO PASTEBOARD(JSON Stringify($html;*))
End if
Even in a text editor, the text is difficult to read, but tools such as VisualJSON or Notepad++ (with the JSONViewer extension) help a lot! Here’s how it looks in VisualJSON:
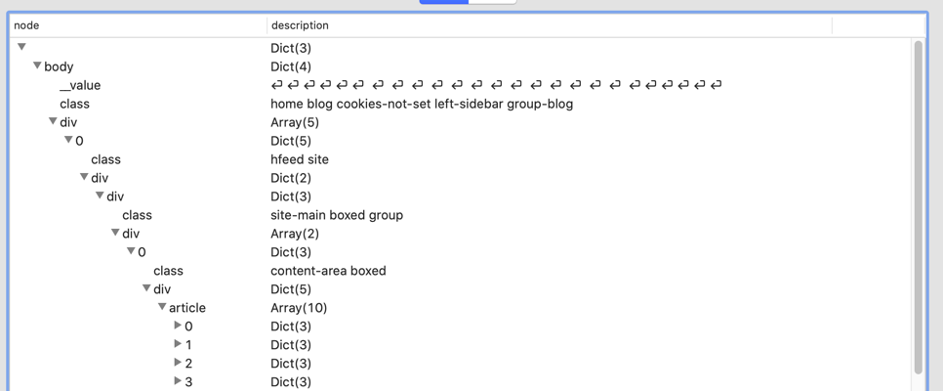
This shows the path to body.div[0].div.div.div[0].div.article.
4D’s debugger provides a similar list:
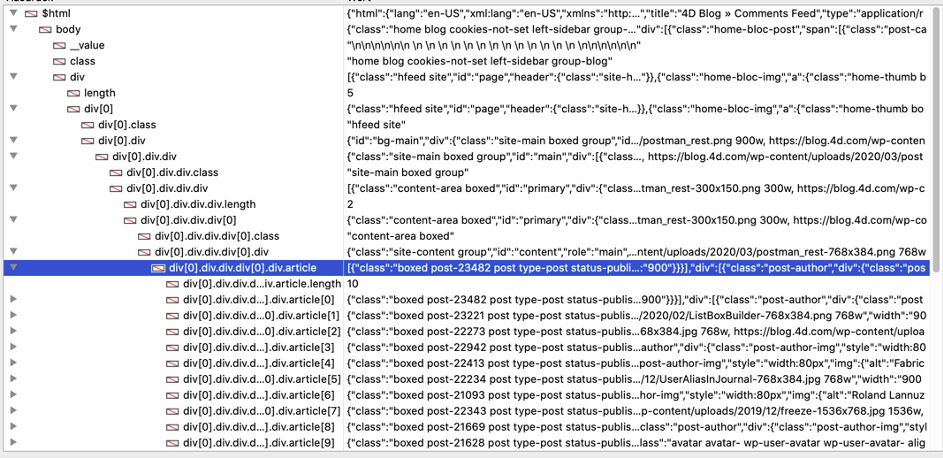
“Article” is a collection and each element contains a single blog post. We can loop through the collection with For Each and access the required fields. “image” is a standard HTML image and src contains the URL, so we get the URL and use HTTP Get to download the image. Finally, the method builds and adjusts the list box to display the data.
In our second example, we retrieve data from a table on Wikipedia:
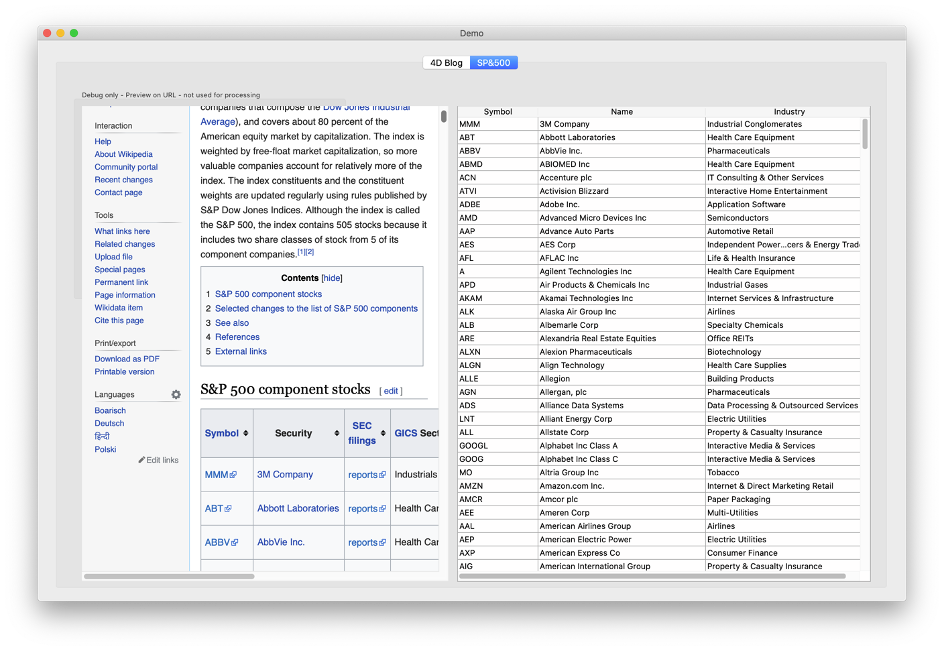
Read the Demo_RunSP500 method to analyze the code.
We follow the same pattern:
We’ll use a little trick to find the object path, because the page is complex and contains several tables (making it impossible to use a normal path). So what’s the trick? Reduce the content by using the first “tbody” element:
$pos:=Position("<tbody>";$answertidy)Then we simply convert the reduced text to an object. Much easier!
$answertidy:=Substring($answertidy;$pos)
$pos:=Position("</tbody>";$answertidy)
$answertidy:=Substring($answertidy;1;$pos+8)
To find this shortcut, we open the page with a browser and check the source to find the elements we’re really interested in. In this example, it’s the first table. Otherwise we would’ve searched for a unique element, such as: <table class=”wikitable sortable” id=”constituents”>.
The element with the <tbody> tag is the one we need. Thanks to the reduced content, we can access the table rows with this code:
$list:=$html.tbody.tr // a collection of table rows
For each ($stock;$list)
$curstock:=New object
If
($stock.th[0]#Null) // ignore the header
Else
$curstock.symbol:=$stock.td[0].a.__value
$curstock.name:=$stock.td[1].a.__value
$curstock.industry:=$stock.td[4].__value
$allstocks.push($curstock)
End if
End for each
Don’t forget to use 4D’s debugger, which also helps find the required elements:

If you’ve ever tried to parse an HTML page using Position/Substring or Regex, you’ll easily see the benefits of using the techniques in this blog post. If you’ve never needed to parse HTML content, it might still be a little challenging at first, but stick with it! It opens new data sources and new ways to get and use available data directly in your applications.
Got a question, suggestion or just want to get in touch with the 4D bloggers? Drop us a line!
* Your privacy is very important to us. Please click here to view our Policy
Comments are not currently available for this post.