
Raspagem da Web usando notação de objectos
Abril 1, 2020
6 Tempo de leitura

Quer recuperar dados que não estão disponíveis via REST ou Web Services? E se só estiver disponível num website? Os dados são suficientemente fáceis de ler para um humano, mas ler dados HTML com uma linguagem de programação não é assim tão simples. Alguns programadores tentam usar Position e Substring, outros tentam Regex, mas é desagradável e demorado. Uma abordagem muito diferente é converter o HTML num objecto e obter os dados através da notação de objecto. As linhas da tabela são tratadas como colecções e são fáceis de passar em loop!
Este post no blogue descreve como utilizar esta abordagem e fornece algumas dicas úteis.
HDI: Raspagem da Web usando objectos
No nosso primeiro exemplo, vamos começar com a página inicial do nosso blog: https://blog.4d.com. Digamos que a nossa tarefa é analisar esta página e exibir a lista de posts do blogue numa caixa de listagem com colunas para autor, imagem, título e conteúdo:
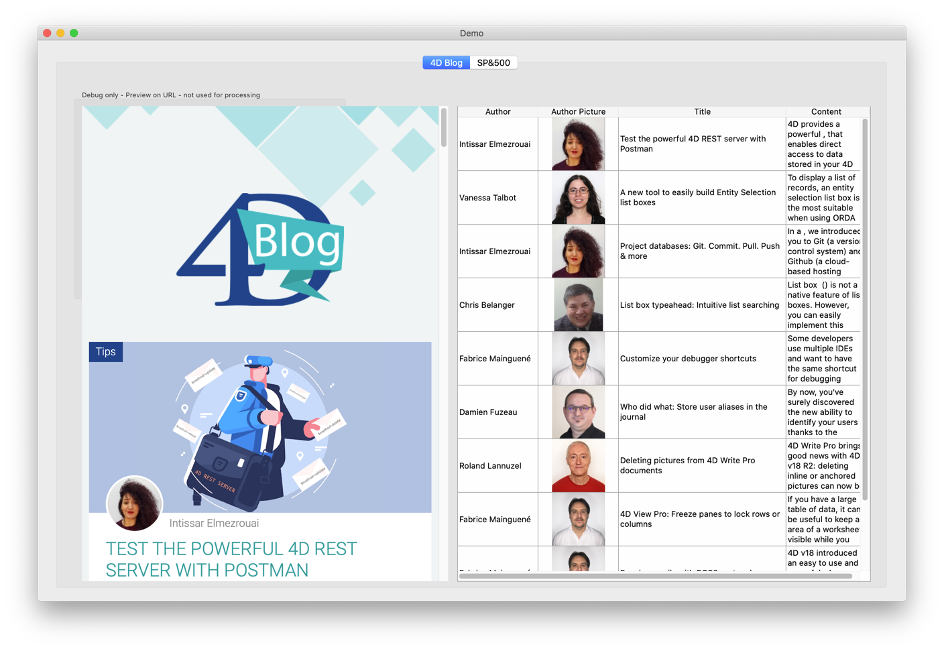
A aplicação demo mostra a página web numa área web à esquerda para comparar e testar (numa aplicação real não mostraríamos isso, claro).
Abra o método Demo_RunBlog para ver como funciona. Aqui estão os passos importantes:
$url:="$status"
:=HTTP Get($url;$answer)
A primeira tarefa é carregar o conteúdo HTML para uma variável de texto. O HTML é muito tolerante; continuará a ser exibido correctamente mesmo que esteja cheio de erros, tais como etiquetas de fecho em falta(por exemplo, uma </p> em falta) ou questões de sintaxe semelhantes. Contudo, isto torna difícil a análise, uma vez que cada tag de abertura pode ou não ter a tag de fecho esperada.
A boa notícia é que existe uma ferramenta para corrigir problemas como este, é chamada “arrumar“. Disponível tanto para Mac como para Windows, pode ser integrada numa aplicação 4D e chamada com o comando LAUNCH EXTERNAL PROCESS.
Estamos a utilizá-la aqui:
$answertidy:=RunTidy ($answer) // make it conform to XML
Se estiver curioso, pode verificar o conteúdo de XMLToObject se quiser ver como funciona, mas não é necessário utilizá-lo. Uma vez que o conteúdo esteja num objecto, podemos utilizar a notação de objecto para aceder directamente a elementos:
$articles:=$html.body.div[0].div.div.div[0].div.article )
$blogposts :=New collection // collect the data
For each ($article;$articles)
$authorurl :=String($article.div[0].div[0].div.img.src)
$authorname :=String($article.div[0].div[0].span.a.__value)
$title :=String($article.div[0].span[1].a.title)
...
$blogposts .push(New object("autor";$authorname; "picturl";$authorurl; "pict";$pict; "title";$title; "content";$content)
End for each
Embora pareça bastante simples, o desafio reside em conhecer a posição do objecto. Assim que soubermos isto, escrever a posição (como.body.div[0]….div.article) é fácil.
Para determinar como uma página web é construída, exibi-la num navegador e abrir o depurador ou inspector do navegador web:
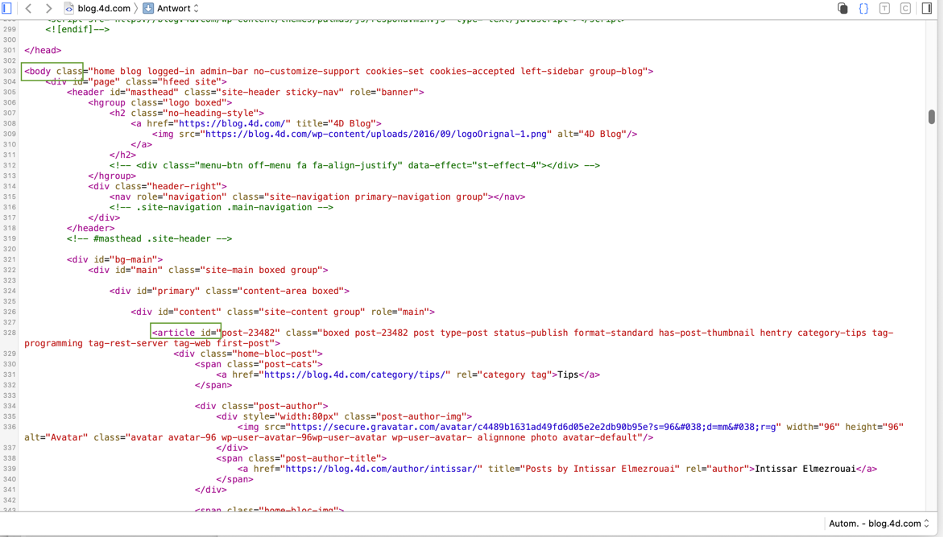
Para este exemplo, precisamos de encontrar o caminho de “corpo” para “artigo“(ou seja, o primeiro artigo do blog). O depurador fornece pistas, mas encontrar o caminho ainda é difícil. Seria mais fácil se pudéssemos formatá-lo directamente como uma lista hierárquica, por isso vamos rastrear através do método e definir o ponteiro de execução para o bloco False:
If (False) // this helps find the path in the object )
SET TEXT TO PASTEBOARD (JSON Stringify($html;*))
End if
Mesmo num editor de texto, o texto é difícil de ler, mas ferramentas como o VisualJSON ou o Notepad++ (com a extensão JSONViewer) ajudam muito! Eis como fica no VisualJSON:
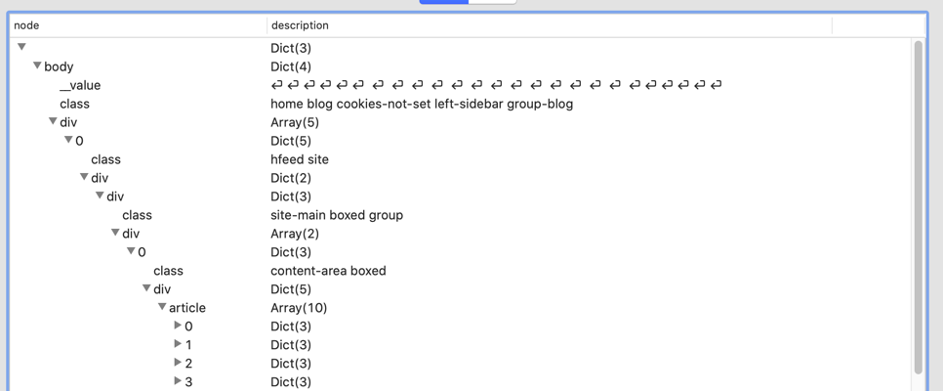
Isto mostra o caminho para body.div[0].div.div.div[0].div.article.
O depurador 4D fornece uma lista semelhante:
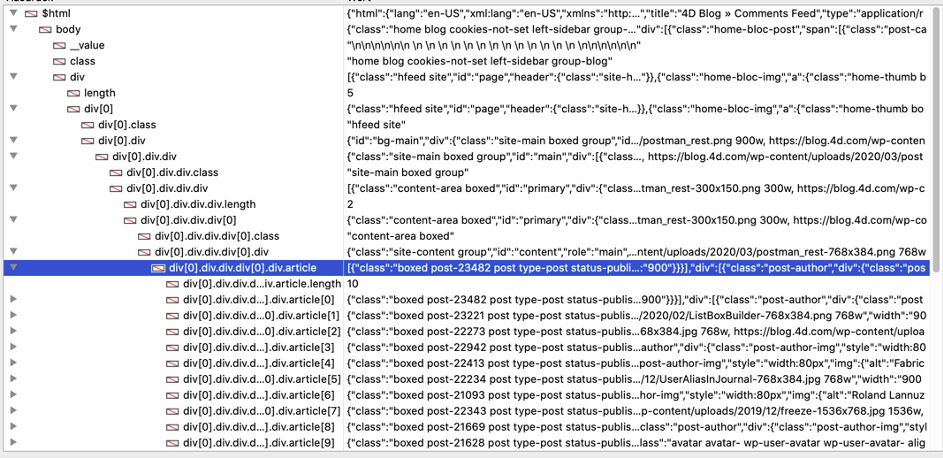
“Artigo” é uma colecção e cada elemento contém um único post no blogue. Podemos percorrer a colecção com For Each e aceder aos campos necessários.“imagem” é uma imagem HTML padrão e src contém o URL, pelo queobtemos o URL e utilizamos HTTP Get para descarregar a imagem. Finalmente, o método constrói e ajusta a caixa de listagem para exibir os dados.
No nosso segundo exemplo, recuperamos dados de uma tabela na Wikipedia:
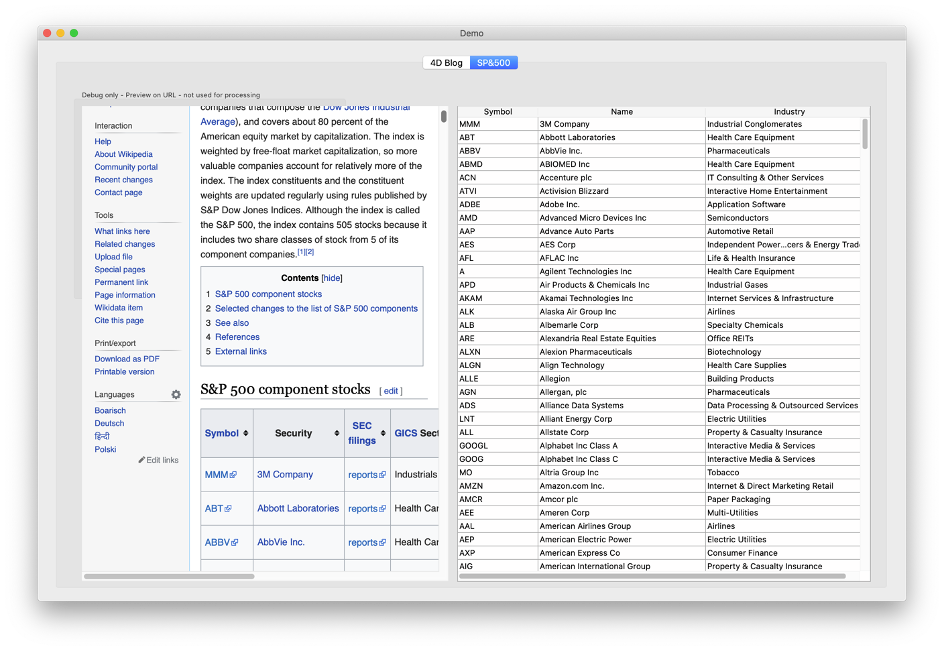
Leia o método Demo_RunSP500 para analisar o código.
Seguimos o mesmo padrão:
Usaremos um pequeno truque para encontrar o caminho do objecto, porque a página é complexa e contém várias tabelas (tornando impossível a utilização de um caminho normal). Então, qual é o truque? Reduzir o conteúdo utilizando o primeiro elemento “tbody”:
$pos:=Position("<tbody>";$answertidy)
$answertidy :=Substring($answertidy;$pos)
$pos :=Position("</tbody>";$answertidy)
$answertidy :=Substring($answertidy;1;$pos+8)Depois simplesmente convertemos o texto reduzido para um objecto. Muito mais fácil!
Para encontrar este atalho, abrimos a página com um browser e verificamos a fonte para encontrar os elementos em que estamos realmente interessados. Neste exemplo, é a primeira tabela. Caso contrário, teríamos procurado um elemento único, tal como: <table class=”wikitable sortable” id=”constituents”>.
O elemento com a <tbody> tag é o elemento de que precisamos. Graças ao conteúdo reduzido, podemos aceder às linhas da tabela com este código:
$list$stocktd:=$html.tbody.tr // a collection of table rows
For each ($stock;$list)
$curstock :=New object
If
($stock.th. // ignore the header [0]#Null) $curstock
Else
.symbol:=$stock.td[0].a.__value
$curstock .name:=$stock.td [1].a.__value
$curstock .industry__value
$allstocks.push($curstock)
End if
End for each
Não se esqueça de utilizar o depurador 4D, que também ajuda a encontrar os elementos necessários:

Se alguma vez tentou analisar uma página HTML usando Position/Substring ou Regex, verá facilmente os benefícios de usar as técnicas neste post do blogue. Se nunca precisou de analisar o conteúdo HTML, pode ainda ser um pouco desafiante no início, mas mantenha-se fiel a ele! Abre novas fontes de dados e novas formas de obter e utilizar os dados disponíveis directamente nas suas aplicações.
Tem uma pergunta, sugestão ou apenas quer entrar em contacto com os bloggers 4D? Deixe-nos uma linha!
* A sua privacidade é muito importante para nós. Por favor clique aqui para ver os nossos Política
De momento, não é possível deixar comentários nesta publicação.