
4D Backup, snapshot VSS e i nuovi comandi per bloccare il datastore
Aprile 25, 2023
6 Tempo di lettura

4D offre diverse modalità integrate per il backup dei dati: Il backup di 4D e l’uso di un server mirror. Con 4D v20, 4D espone comandi interni per bloccare il datastore, consentendo di copiare i dati mentre 4D è in esecuzione.
Per prima cosa, parliamo dei diversi mezzi per eseguire il backup dei dati con 4D.
Il backup integrato non solo esegue una copia completa automatica del file di dati, ma gestisce anche un registro delle transazioni contenente tutte le operazioni che avvengono nei dati. Questa è la migliore protezione per il vostro lavoro. Se succede qualcosa, come una perdita di potenza, un disco rigido danneggiato o un crash del sistema, all’avvio successivo 4D rileverà automaticamente il guasto e, se necessario, integrerà le operazioni mancanti dal registro o eseguirà un ripristino completo con integrazione del registro. Ecco perché consigliamo 4D Backup per la maggior parte dei casi d’uso.
Per maggiori dettagli, leggete https://developer.4d.com/docs/Backup/overview.
Per le installazioni 24/7 in cui non è possibile bloccare il file di dati per un backup completo o in cui si desidera un tempo di ripristino minimo, è necessario utilizzare un server mirror. 4D replicherà automaticamente tutte le modifiche sul server mirror, quindi se il server principale si guasta il server mirror può essere attivo in pochi secondi.
L’impostazione di una configurazione mirror richiede più lavoro ed è più complicata rispetto all’utilizzo del backup. Abbiamo già aiutato molti dei nostri clienti a implementare questa configurazione, quindi non esitate a contattare il team di assistenza professionale di 4D per ricevere assistenza e consigli.
Soprattutto negli ambienti virtuali, gli amministratori di sistema preferiscono utilizzare snapshot basati su Volume Shadow Copy (VSS). 4D supporta questa funzione con il proprio 4D VSS Writer. Leggete https://blog.4d.com/enterprise-virtual-machine-snapshot-support/ per i dettagli.
Fate attenzione perché non sostituisce 4D Backup, in quanto un’istantanea contiene solo i dati di un determinato momento. Tutte le operazioni avvenute dopo l’istantanea non possono essere recuperate perché mancano il journal e il registro delle transazioni.
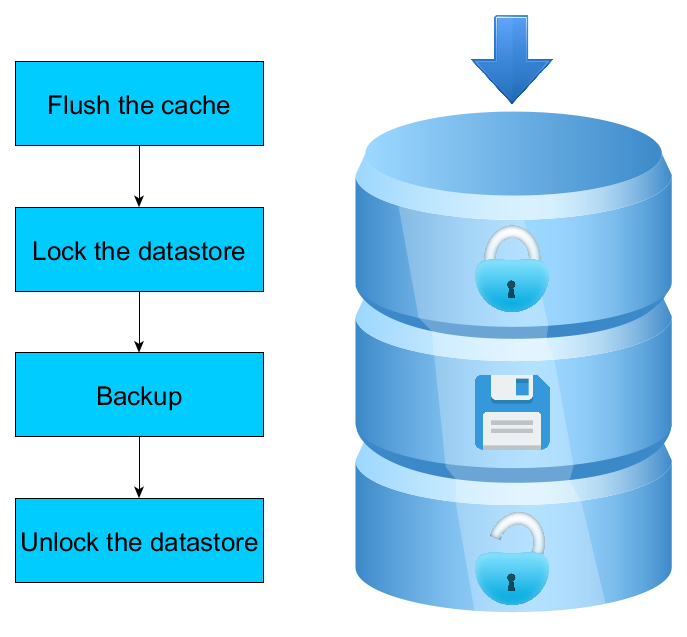
Una spiegazione visiva del funzionamento di 4D Backup
Lascerò da parte il backup mirror, che è un modo molto diverso di salvare i dati, e mi concentrerò sul funzionamento di 4D Backup e 4D VSS.
Il primo punto da tenere in considerazione è che 4D non applica immediatamente ogni modifica al file di dati in tempo reale. Ciò richiederebbe un numero eccessivo di accessi al disco, incidendo in modo significativo sulle prestazioni dell’applicazione. 4D utilizza una cache in memoria, dove tutte le modifiche vengono applicate per prime, e regolarmente 4D svuota la cache, applicando tutte le modifiche al file di dati in una sola volta. Pertanto, all’avvio del backup o quando viene richiamato il VSS, 4D esegue prima il lavaggio della cache affinché il file di dati contenga dati aggiornati.
Un altro punto importante da tenere in considerazione è che la copia di un file di dati mentre è in uso non funziona: Se il file di dati viene modificato durante la copia, il file di dati risultante può essere danneggiato o si possono avere differenze tra il file di dati e il journal o gli indici. Il secondo passo consiste quindi nel bloccare il file di dati impedendo le operazioni di scrittura durante la copia. Le operazioni di lettura sono ancora supportate, ma ogni processo che tenta di eseguire un’operazione di scrittura viene bloccato fino al termine del backup/istantanea VSS.
Infine, vorrei parlarvi del diario. Il journal contiene tutte le operazioni effettuate dall’ultimo backup. Viene utilizzato in due casi principali: Se il file di dati viene danneggiato o se si desidera ripristinare alcune operazioni sfortunate dell’utente. Si tratta di un file molto importante se non si vuole perdere nemmeno una modifica del file di dati.
Quindi, una volta svuotata la cache e bloccato il file di dati, 4D backup (ma non VSS) crea un nuovo file journal. Quindi è possibile copiare il file di dati, il file di indice e il journal, prima di sbloccare i dati.
Come si può vedere, l’intera operazione è piuttosto complessa. Per questo motivo incoraggiamo vivamente i nostri clienti a utilizzare il backup 4D, che è completamente automatizzato e sicuro. Tuttavia, alcuni di voi costruiscono il proprio meccanismo di snapshot. Per loro, abbiamo introdotto la possibilità di bloccare il datastore mentre 4D è in esecuzione!
Abbiamo fornito 3 nuovi comandi: ds.flushAndLock(), ds.locked() e ds.unlock().
ds.flushAndLock() esegue il lavaggio della cache e blocca il datastore per gli altri processi. Mentre il datastore è bloccato, tutte le operazioni di scrittura provenienti da altri processi vengono messe in attesa finché non viene sbloccato. In questo modo, da quel momento in poi, si sa che né il file di dati, né il file di indice, né il journal verranno alterati, consentendo di copiarli liberamente e di essere sicuri che siano sincronizzati e non corrotti.
Una volta terminata la copia, si può chiamare ds.unlock() nello stesso processo. In questo modo si rilascerà il blocco sul datastore, consentendo nuovamente le operazioni di scrittura.
Il comando ds.locked() indica se un processo ha attualmente bloccato il datastore.
Con questi tre comandi è possibile riprodurre il modo in cui 4D backup e VSS bloccano il datastore prima di copiarlo.
Per illustrare questa nuova funzionalità, vi forniamo un frammento di codice. Questo codice esegue un’archiviazione della cartella dati (e quindi dei file di dati e indice) e del giornale:
$destination:=Folder(fk documents folder).folder("Archive")
$destination.create() // The folder where we will copy the archive
ds.flushAndLock() // We first lock the datastore, blocking write operations from other processes
$dataFolder:=Folder(fk data folder)
$dataFolder.copyTo($destination) // We can now copy the data folder
$oldJournalPath:=New log file() // We create a new journal
$oldJournal:=File($oldJournalPath; fk platform path)
$oldJournal.moveTo($destination) // We move the old journal
ds.unlock() // Our copy is over, we can now unlock the datastore
Come si può notare, anche se il codice è piuttosto piccolo, devono essere eseguiti molti passaggi importanti per essere sicuri che l’archivio non venga danneggiato: il codice si occupa di svuotare la cache e di bloccare il datastore, di creare un nuovo diario e di salvare quello vecchio e, naturalmente, di sbloccare il datastore al termine dell’operazione. Vi invito a utilizzare questo pezzo di codice come base per i vostri meccanismi di snapshot, in modo da non dimenticare un passaggio importante.
Per ora è tutto. Spero che questo post vi aiuti a capire meglio il funzionamento interno di 4D Backup.
E naturalmente, se avete domande o commenti, non esitate a farli nel forum.
Avete domande, suggerimenti o volete semplicemente entrare in contatto con i blogger di 4D? Lasciateci un messaggio!
* La vostra privacy è molto importante per noi. Fare clic qui per visualizzare il nostro Politica
Al momento non è possibile lasciare commenti su questo post.