
4D Backup, VSS snapshots et les nouvelles commandes pour verrouiller le datastore
avril 25, 2023
7 min de lecture

4D vous offre plusieurs moyens intégrés de sauvegarder vos données : La sauvegarde 4D et l’utilisation d’un serveur miroir. Avec 4D v20, 4D expose des commandes internes pour verrouiller le datastore, ce qui vous permet de copier vos données pendant que 4D est en cours d’exécution.
Tout d’abord, parlons des différents moyens de sauvegarder vos données avec 4D.
La sauvegarde intégrée ne se contente pas de faire une copie complète et automatique de votre fichier de données, elle gère également un journal des transactions contenant toutes les opérations effectuées sur vos données. C’est la meilleure protection pour votre travail. Si quelque chose se produit, comme une coupure de courant, un disque dur endommagé ou un crash du système, au prochain démarrage, 4D détectera automatiquement la panne et – si nécessaire – intégrera les opérations manquantes dans le journal ou lancera une restauration complète avec intégration du journal. C’est pourquoi nous recommandons 4D Backup pour la plupart des cas d’utilisation.
Pour plus de détails, consultez le site https://developer.4d.com/docs/Backup/overview.
Pour les installations 24/7 où vous ne pouvez pas verrouiller le fichier de données pour une sauvegarde complète ou lorsque vous voulez un temps de restauration minimum, vous devez utiliser un serveur miroir. 4D répliquera automatiquement tous les changements sur le serveur miroir, de sorte que si votre serveur principal tombe en panne, votre serveur miroir peut être opérationnel en quelques secondes.
La mise en place d’une configuration miroir demande plus de travail et est plus compliquée que l’utilisation du backup. Nous avons déjà aidé un grand nombre de nos clients à déployer cette configuration, n’hésitez donc pas à contacter l’équipe du service professionnel de 4D pour obtenir de l’aide et des conseils.
Les administrateurs système aiment utiliser des snapshots basés sur Volume Shadow Copy (VSS), en particulier dans les environnements virtuels. 4D supporte ceci avec son propre 4D VSS Writer. Consultez https://blog.4d.com/enterprise-virtual-machine-snapshot-support/ pour plus de détails.
Attention, cela ne remplace pas 4D Backup car un snapshot ne contient que les données d’un moment donné. Toutes les opérations qui se sont produites après le snapshot ne peuvent pas être récupérées car il manque le journal.
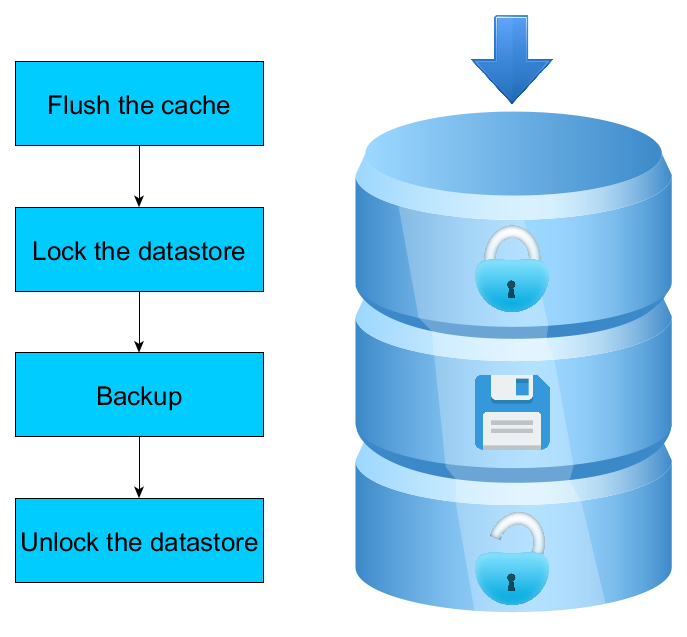
Explication visuelle du fonctionnement de 4D Backup
Je vais laisser de côté le server miroir, qui est une façon très différente de sauvegarder vos données, et me concentrer sur le fonctionnement de 4D Backup et 4D VSS.
Le premier point à prendre en considération est que 4D n’applique pas les changements sur le fichier de données en temps réel. Cela nécessiterait un trop grand nombre d’accès au disque, ce qui affecterait considérablement les performances de votre application. 4D utilise un cache en mémoire, où toutes les modifications sont d’abord appliquées, puis régulièrement 4D vide le cache, appliquant toutes les modifications sur le fichier de données en une seule passe. Ainsi, lorsque la sauvegarde démarre ou que VSS est appelé, 4D vide d’abord le cache pour que le fichier de données contienne des données à jour.
Un autre point important à prendre en considération est que la copie d’un fichier de données en cours d’utilisation ne fonctionne pas : Si le fichier de données est modifié pendant la copie, le fichier de données résultant peut être corrompu ou vous pouvez avoir des différences entre le fichier de données et le journal ou les index. La deuxième étape consiste donc à verrouiller le fichier de données en empêchant les opérations d’écriture pendant la copie. Les opérations de lecture sont toujours prises en charge, mais chaque processus qui tente d’effectuer une opération d’écriture sera bloqué jusqu’à la fin du backup/snapshot VSS.
Enfin, parlons du journal. Le journal contient toutes les opérations que vous avez effectuées depuis votre dernière sauvegarde. Il est utilisé dans deux cas principaux : Si votre fichier de données est corrompu ou si vous voulez annuler certaines opérations malheureuses de l’utilisateur. Ce fichier est très important si vous ne voulez pas perdre une seule modification de votre fichier de données.
Ainsi, une fois que le cache est vidé et que le fichier de données est verrouillé, le backup 4D (mais pas VSS) crée un nouveau fichier journal. Ensuite, le fichier de données, le fichier d’index et le journal peuvent être copiés, avant de déverrouiller les données.
Comme vous pouvez le constater, l’opération est assez complexe. C’est pourquoi nous encourageons vivement nos clients à utiliser le backup, qui est à la fois entièrement automatisé et sûr. Cependant, certains d’entre vous veulent construire leur propre mécanisme de snapshot. Pour eux, nous avons apporté la possibilité de verrouiller le datastore pendant que 4D est en cours d’exécution !
Nous vous avons fourni 3 nouvelles commandes : ds.flushAndLock(), ds.locked() et ds.unlock().
ds.flushAndLock() vide le cache et verrouille le datastore pour les autres processus. Tant que le datastore est verrouillé, toutes les opérations d’écriture provenant d’autres processus sont mises en attente jusqu’à ce qu’il soit déverrouillé. À partir de ce moment, vous savez que ni votre fichier de données, ni votre fichier d’index, ni votre journal ne seront altérés, ce qui vous permet de les copier librement et de vous assurer qu’ils sont synchronisés et non corrompus.
Une fois la copie terminée, vous pouvez appeler ds.unlock() dans le même processus. Cela libérera le verrou sur le magasin de données, permettant ainsi aux opérations d’écriture d’avoir lieu à nouveau.
La commande ds.locked() vous indiquera si un processus a verrouillé le datastore.
Avec ces 3 commandes, vous pouvez maintenant reproduire la façon dont 4D backup et VSS verrouillent le datastore avant de le copier.
Pour illustrer cette nouvelle fonctionnalité, laissez-moi vous donner un extrait de code. Ce code effectue une archive du dossier de données (et donc des fichiers de données et d’index) et du journal :
$destination:=Folder(fk documents folder).folder("Archive")
$destination.create() // The folder where we will copy the archive
ds.flushAndLock() // We first lock the datastore, blocking write operations from other processes
$dataFolder:=Folder(fk data folder)
$dataFolder.copyTo($destination) // We can now copy the data folder
$oldJournalPath:=New log file() // We create a new journal
$oldJournal:=File($oldJournalPath; fk platform path)
$oldJournal.moveTo($destination) // We move the old journal
ds.unlock() // Our copy is over, we can now unlock the datastore
Comme vous pouvez le constater, même si le code est assez petit, de nombreuses étapes importantes doivent être effectuées pour s’assurer que l’archive n’est pas corrompue : le code se charge de vider le cache et de verrouiller le datastore, de créer un nouveau journal et de sauvegarder l’ancien, et bien sûr de déverrouiller le datastore à la fin de l’opération. Je vous encourage à utiliser ce code comme base pour vos propres mécanismes de snapshot afin de ne pas oublier une étape importante.
C’est tout pour l’instant. J’espère que ce billet vous aidera à mieux comprendre le fonctionnement interne de 4D Backup.
Et bien sûr, si vous avez des questions ou des commentaires, n’hésitez pas à les apporter sur le forum.
Vous avez une question, une suggestion ou vous voulez simplement entrer en contact avec les blogueurs 4D ? Envoyez-nous un message !
* Votre vie privée est très importante pour nous. Veuillez cliquer ici pour consulter notre Politique
Les commentaires ne sont pas disponibles pour cet article pour le moment.