
Uma nova ferramenta na ponta dos seus dedos para analisar registos de depuração
Julho 31, 2019
6 Tempo de leitura

Com 4D v17 R5, melhorámos os registos de depuração adicionando métodos e permitindo que cada processo seja rastreado de forma independente. Com este lançamento R, demos um passo em frente ao enviar uma ferramenta de análise de registos de depuração para o ajudar a monitorizar a execução do processo. Poderá ver quais os processos que mais consomem, a cadeia de chamadas com o correspondente tempo de execução, e muito mais.
HDI: Analisador de Registos de Depuração
Neste post do blogue, vamos olhar para um cenário onde temos de descobrir porque há respostas lentas de uma base de dados que serve páginas web dinâmicas.
Alguns utilizadores notaram que o website é por vezes lento, mas não podem fornecer mais detalhes. Há várias formas de investigar, por isso vamos dar uma vista de olhos e tentar descobrir o que se passa!
O analisador de registos de depuração baseia-se no formato de ficheiro de registos de depuração 4D v14. Portanto, para activar o registo, basta usar o seguinte código:
//debug logging activado com parâmetros (opção 2), formato de ficheiro 4D v14 (opção 4), e escrita adiada (opção 8))
SET DATABASE PARAMETER (Debug log recording;2+4+8
Tenha em mente que começando com 4D v17 R5, pode permitir a depuração para um único processo. Se suspeitar que um determinado processo é responsável pela latência, é agora fácil e menos demorado iniciar a depuração de registos apenas para esse processo em particular:
SET DATABASE PARAMETER (Current process debug log recording;2+4+8)
O analisador de registos de depuração gere projectos, que são um conjunto de ficheiros de registos de depuração, e uma sessão de registo de depuração.
Quando se abre uma base de dados, é mostrada uma lista de projectos armazenados. É possível criar um projecto usando o botão “Novo “. Tem de escolher a pasta que contém os registos de depuração ou escolher os ficheiros que deseja analisar, e depois dar um nome ao seu projecto.
Tenha em mente que mesmo que o processo de análise esteja a decorrer de forma preemptiva, pode levar tempo, dependendo do número de ficheiros a analisar e dos processadores na sua máquina.
Ao seleccionar o projecto da lista, um resumo exibe informações básicas como a gama dos registos de depuração e as linhas analisadas. Pode visualizar as cadeias de chamadas, estatísticas e detalhes do projecto, clicando nos botões correspondentes.
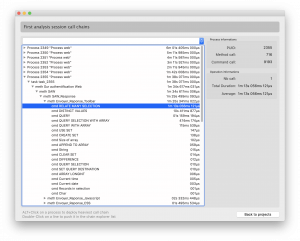
O ecrã da cadeia de chamadas mostra a lista de processos com o tempo total de execução. A lista é ordenada para mostrar os processos mais demorados no topo do ecrã.
É possível alargar a cadeia de chamadas de processo e ver a operação mais demorada em cada nível. Ao clicar num processo com a tecla ALT, estende automaticamente a cadeia de chamadas mais pesada, e ao fazer duplo clique sobre uma operação, move-a para o explorador da cadeia. Pode então seleccionar um nível da lista para refrescar a vista da lista hierárquica no nível correspondente. Para cada comando seleccionado, são exibidos o número total de chamadas, a duração total, e a duração média.
No exemplo abaixo, procurámos os processos e comandos mais consumidores. Podemos ver que o comando RELATE MANY SELECTION pode demorar mais de um minuto a completar, por isso vamos dar uma vista de olhos à secção de informação detalhada e ver onde o comando foi chamado.
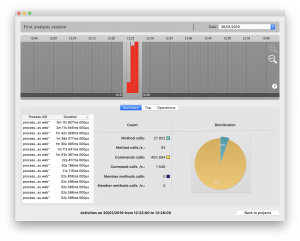
O ecrã detalhado apresenta uma linha temporal da actividade, apresentada minuto a minuto. Pode aumentar ou diminuir o zoom para ver mais ou menos detalhes. Isto permite-lhe seleccionar o intervalo de tempo específico a analisar. Pode seleccionar apenas um ou vários minutos, movendo os limites.
Quando um novo intervalo é seleccionado, é executada uma análise e os resultados são exibidos na parte inferior do ecrã. Ao apontar períodos de actividade elevada, tem outra forma de determinar processos lentos .
O separador Resumo mostra as estatísticas gerais do tempo de execução do processo para o intervalo de tempo seleccionado. É possível comprimir as estatísticas, seleccionando um processo da lista.
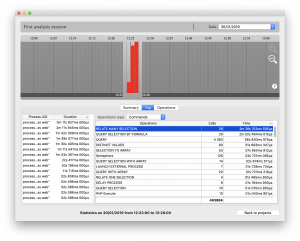
O separador Top mostra todas as operações registadas com o seu número de chamadas e tempo total de execução para os processos escolhidos e intervalo de tempo. A lista pode ser reduzida utilizando um filtro para comandos, métodos, ou métodos de membros. Esta é outra boa forma de determinar os comandos, métodos, etc. mais consumíveis.
Seguindo o nosso exemplo, seleccionámos um intervalo de tempo e filtrámos por comandos. Aparece uma confirmação: o comando RELATE MANY SELECTION é utilizado algumas vezes e demorou muito tempo. Passemos ao passo seguinte para mais detalhes.
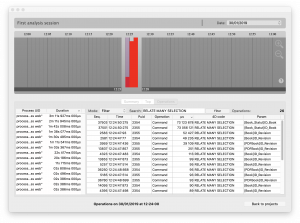
O separador Operações exibe todas as operações detalhadas durante um único minuto, isolado, para os processos escolhidos. Pode reduzir a lista ou simplesmente realçá-la, procurando por uma operação. Esta estatística é limitada a um minuto por razões de desempenho, por isso não se esqueça de seleccionar o minuto em que pretende ver as operações iniciadas!
Esta lista pode ser muito útil porque mostra-lhe todas as linhas de código executadas. Pode também encomendá-la pela coluna.
Para terminar o nosso exemplo, procurámos o comando RELATE MANY SELECTION , filtrámos a lista, e ordenámos pela coluna Duração (para colocar as chamadas mais longas no topo da lista). Parece que as duas chamadas mais demoradas são feitas com o mesmo campo. Um rápido olhar sobre a estrutura da nossa base de dados e encontramos o culpado: o campo precisava de ser indexado.
Esta ferramenta foi concebida para o ajudar a encontrar conflitos no seu código e a melhorar o desempenho da sua base de dados. Sujem as vossas mãos e divirtam-se a investigar descarregando o HDI acima!
Tem uma pergunta, sugestão ou apenas quer entrar em contacto com os bloggers 4D? Deixe-nos uma linha!
* A sua privacidade é muito importante para nós. Por favor clique aqui para ver os nossos Política
De momento, não é possível deixar comentários nesta publicação.