
4D AI: Entdecken Sie die Leistungsfähigkeit von 4D Vectors
August 1, 2025
6 Lesezeit

Bei der Arbeit mit modernen Anwendungen, insbesondere solchen, die mit künstlicher Intelligenz, natürlicher Sprachverarbeitung oder räumlichen Daten zu tun haben, ist Vektormathematik der Schlüssel. Aus diesem Grund führt 4D 20 R10 ein neues Objekt ein: 4D.VectorDieses Objekt wurde entwickelt, um Entwicklern zu helfen, Datenvektoren mit nur ein paar Zeilen Code zu speichern und zu vergleichen.
Wenn Sie beispielsweise eine Funktion entwickeln, mit der Sie Bilder danach bewerten können, wie gut sie mit einer Textaufforderung übereinstimmen, erzeugen Sie einfach Vektoren, vergleichen Sie sie mit Hilfe der Kosinus-Ähnlichkeit und sortieren Sie Ihre Ergebnisse von der höchsten bis zur niedrigsten Relevanz, alles direkt in 4D.
Die Integration von künstlicher Intelligenz ist nicht nur ein Trend – sie wird zu einem Schlüsselfaktor für moderne Geschäftsanwendungen. Aus diesem Grund investiert 4D intensiv in native KI-Funktionen, um Sie zu unterstützen. Mit 4D 20 R10 beginnt die Unterstützung für Vektordaten mit der Einführung von 4D.Vector – und legt damit den Grundstein für ein noch leistungsfähigeres Feature-Set in 4D 21.
Diese erste Version gibt erfahrenen Entwicklern die Werkzeuge an die Hand, um intelligentere, KI-gestützte Funktionen direkt in ihre 4D Anwendungen zu integrieren. Aber das ist erst der Anfang. Wichtige Erweiterungen wie ein Vektorindex – wichtig für die Skalierung der Leistung – werden noch kommen. In der Zwischenzeit konzentrieren wir uns auf reale Anwendungsfälle, die zeigen, was heute möglich ist, einschließlich semantischer Suche und natürlichem Sprachabgleich.
Im Grunde genommen ist ein Vektor nur eine Liste von Zahlen, aber diese Zahlen stehen für etwas Sinnvolles.
In der künstlichen Intelligenz verwenden wir Vektoren, um komplexe Dinge wie Wörter, Bilder oder sogar das Verhalten von Kunden auf eine Weise zu beschreiben, die Maschinen vergleichen können. Jede Zahl in der Liste erfasst einen Teil der Bedeutung dieser Sache: ihren Ton, ihren Stil, ihr Thema oder ihren Kontext.
Zum Beispiel könnte das Wort „Apfel“ zu einem Vektor wie [0,12, -0,45, 0,78, …] werden. Diese Zahlen spiegeln wider, wie das Wort in der Sprache verwendet wird, vielleicht im Zusammenhang mit Obst, vielleicht mit einem Technologieunternehmen, je nach Kontext.
Diese Vektoren befinden sich in einem hochdimensionalen Raum, in dem ähnliche Bedeutungen nahe beieinander liegen und nicht verwandte Dinge weit voneinander entfernt sind.
Diese Struktur macht Vergleiche einfach:
„Ist dieses Bild konzeptionell nah an dieser Aufforderung?“
„Sprechen diese beiden Dokumente von derselben Sache?“
Mit Hilfe der Vektormathematik, z. B. der Cosinus-Ähnlichkeit, können wir messen, wie nahe zwei Vektoren beieinander liegen. Je näher sie beieinander liegen, desto ähnlicher ist die Bedeutung. Auf diese Weise funktionieren moderne Funktionen wie semantische Suche, Empfehlungen und Klassifizierung.
Ab 4D 20 R10 können Sie dank eines neuen nativen Objekts jetzt direkt in Ihrem Code mit Vektoren arbeiten: 4D.Vector.
Es wurde entwickelt, um Vektormathematik einfach und zugänglich zu machen, damit Sie hochdimensionale Daten speichern, vergleichen und sortieren können, ohne auf externe Bibliotheken angewiesen zu sein. Müssen Sie messen, wie ähnlich sich zwei Elemente sind? Rufen Sie einfach die eingebauten Methoden wie Kosinusähnlichkeit, Punktprodukt oder Euklidischer Abstand auf – alles direkt in 4D.
Es gibt zwei einfache Möglichkeiten, einen Vektor zu erstellen 4D.Vectorzu erstellen, je nachdem, woher Ihre Daten stammen:
Wenn Sie einen Text in einen Vektor umwandeln möchten, um beispielsweise Ideen zu vergleichen oder die semantische Suche zu unterstützen, können Sie das Einbettungsmodell von OpenAI über 4D AI Kit verwenden:
var $AIKey:="tDGWULQsrG..."
var $clientAI:=cs.AIKit.OpenAI.new($AIKey)
var $inputText:="Apple"
// Name of the embedding model to use
var $model:="text-embedding-ada-002"
// Call the OpenAI embeddings API to generate the vector for the input text
var $result:=$clientAI.embeddings.create($inputText; $model)
Var $myVector:=$result.embedding.vector
// $myVector=[0.013417294,-0.005096785,-0.001601552,-0.04005942,...]Damit erhalten Sie eine Liste von Gleitkommazahlen, die die Bedeutung Ihrer Eingabe erfassen. Sie können sie nun für Vergleiche, Ranglisten oder Klassifizierungsaufgaben verwenden.
Wenn Sie bereits Vektordaten haben – vielleicht von einem externen Dienst oder Modell – können Sie eine 4D.Vector manuell erstellen:
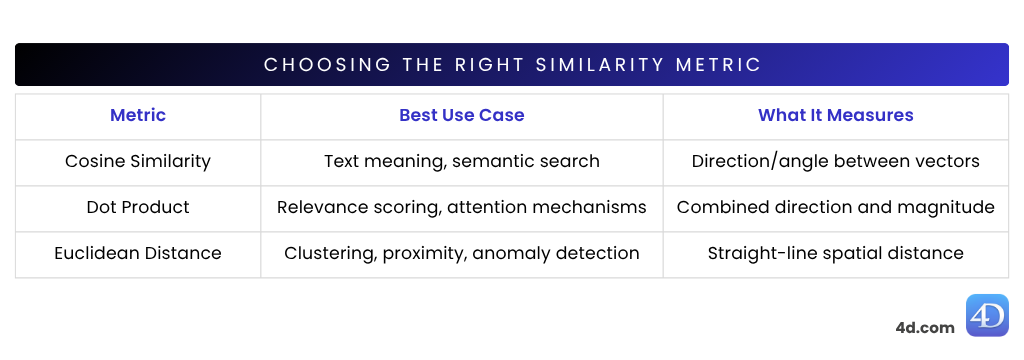
var $vector := 4D.Vector.new([0.123; -0.456; 0.789])Die Cosinus-Ähnlichkeit ist eine der am häufigsten verwendeten Ähnlichkeitsmetriken in der natürlichen Sprachverarbeitung (NLP) – ideal für den Vergleich der Bedeutung von Sätzen oder Dokumenten. Sie misst, wie sehr zwei Vektoren in dieselbe Richtung weisen, und zwar auf der Grundlage des Winkels zwischen ihnen, nicht ihrer Größe.

var $anotherVector := 4D.Vector.new([0.598; -0.951; 0.789])
var $similarity := $vector.cosineSimilarity($anotherVector)
// $similarity = 0,8949424061203Bereich: -1 (entgegengesetzt) bis 1 (identisch)
Gut geeignet für: Vergleich von Satzeinbettungen, semantische Suche und Dokumentenklassifizierung
Die Punktähnlichkeit (auch Skalarprodukt genannt) kombiniert sowohl die Richtung als auch die Länge der Vektoren. Das bedeutet, dass nicht nur untersucht wird, wie sehr zwei Vektoren aufeinander ausgerichtet sind, sondern auch, wie stark sie sind.
Wenn zwei Vektoren in eine ähnliche Richtung zeigen und große Beträge haben, ist das Punktprodukt hoch, was durch dickere Pfeile im Diagramm angezeigt wird.
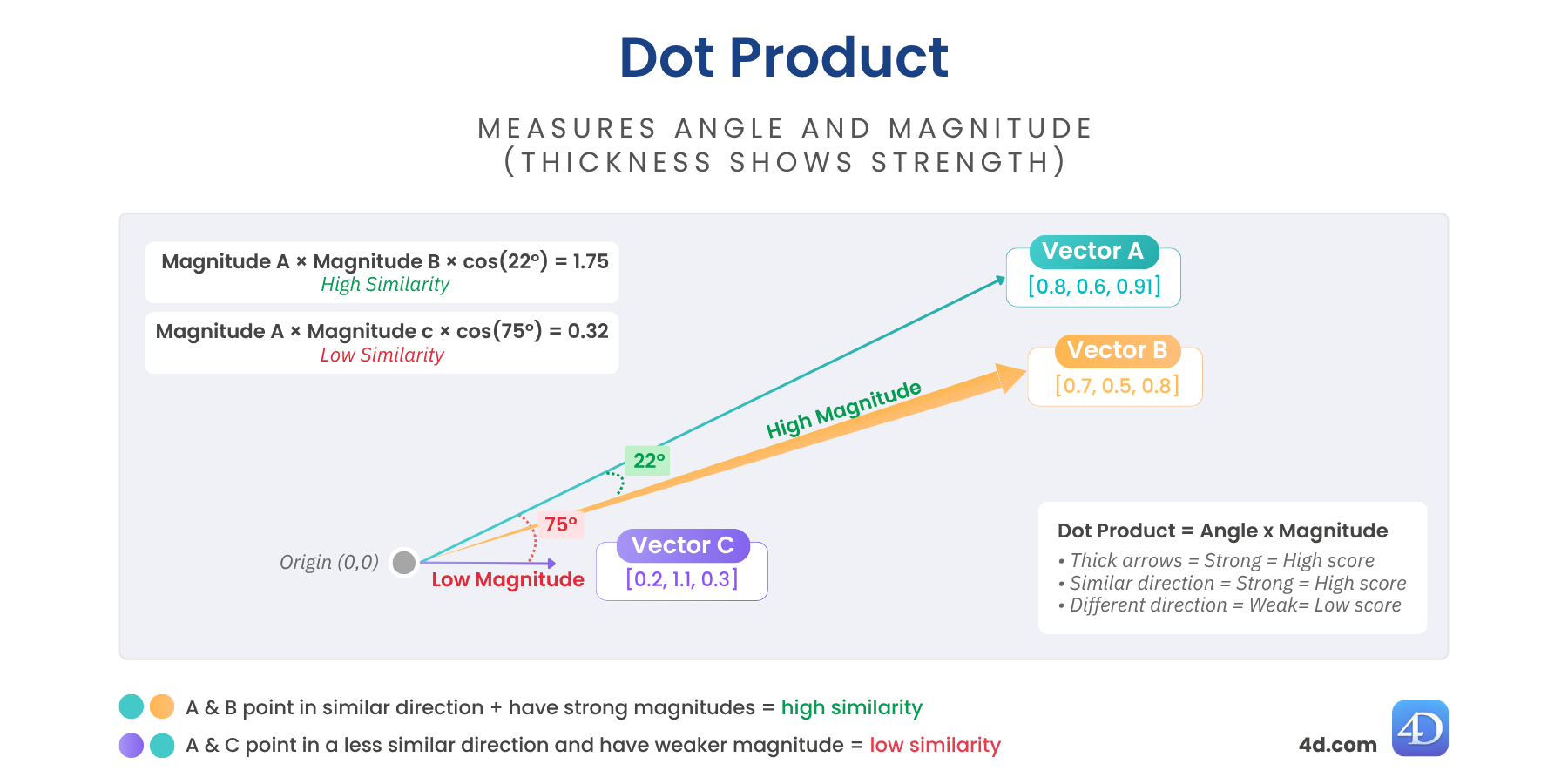
var $score := $vector.dotSimilarity($anotherVector)
// $score = 1,129731Höhere Werte bedeuten mehr Ähnlichkeit und eine stärkere Ausrichtung.
Hervorragend geeignet für: Empfehlungsmaschinen, Transformationsmodelle, fein abgestimmte Einbettungen
Der euklidische Abstand ist ein echtes Maß für die Unähnlichkeit von Vektoren. Er zeigt an, wie weit zwei Vektoren im Raum voneinander entfernt sind – je näher sie beieinander liegen, desto ähnlicher ist ihre Bedeutung. Je weiter sie voneinander entfernt sind, desto unterschiedlicher sind sie.
Es ist perfekt, wenn Sie ein echtes Maß für die Unähnlichkeit benötigen – ideal für Clustering, die Erkennung von Anomalien oder geografische Schlussfolgerungen.
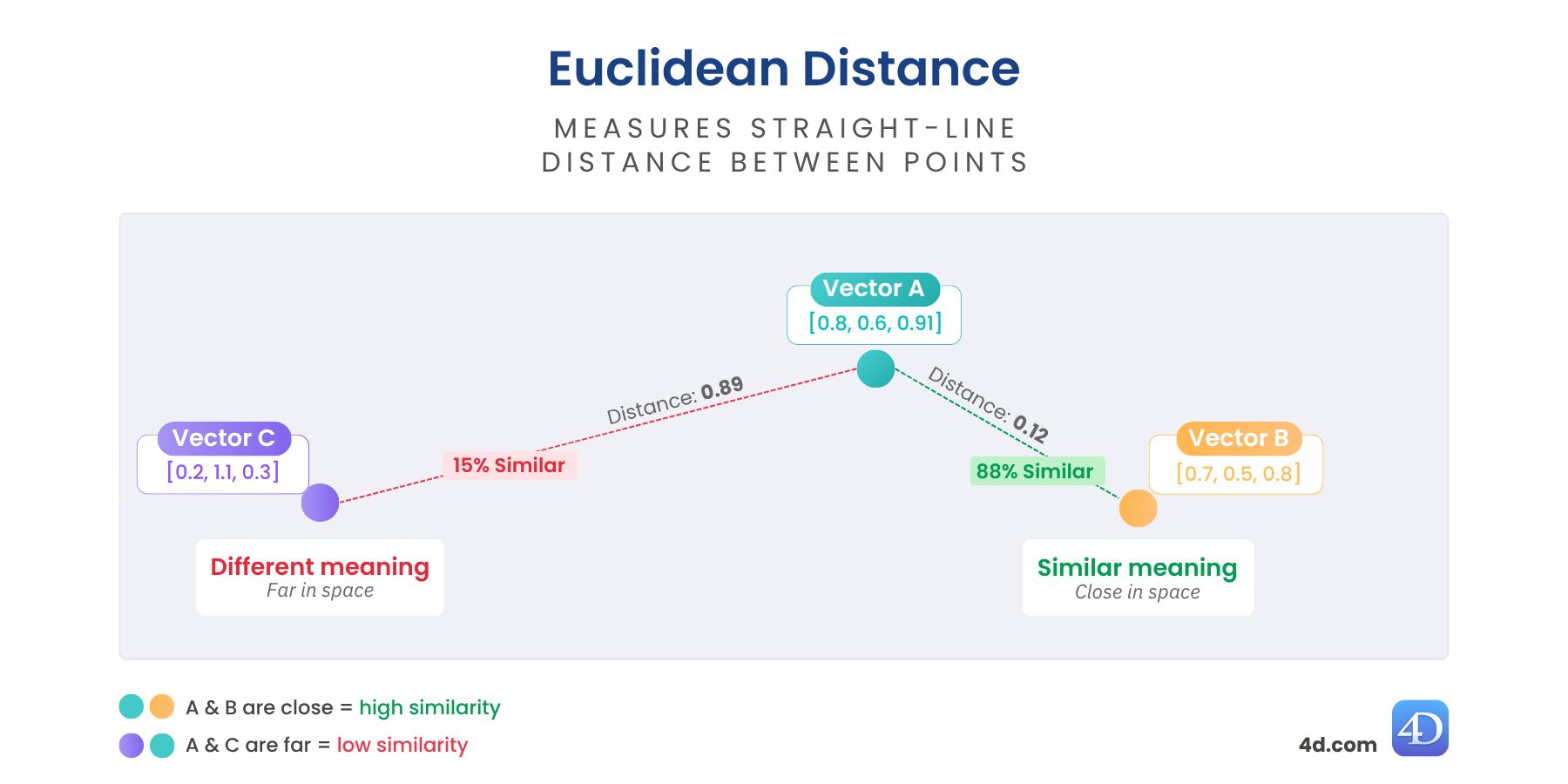
var $distance := $vector.euclideanDistance($anotherVector)
//$distance = 0,6860393574716Niedriger = ähnlicher
Ideal für: strukturierte Daten, Erkennung von Anomalien oder räumliche Nähe
Das 4D.Vector Objekt legt den Grundstein für eine ganze Reihe neuer Funktionen in Ihren Anwendungen. Mit nur ein paar Zeilen Code können Sie:
Suchwerkzeuge erstellen, die die Absicht verstehen
Empfehlungen mit echtem Kontext ausstatten
Daten auf der Basis von Bedeutung und nicht nur von Metadaten einordnen, gruppieren und filtern
Und das alles läuft nativ in 4D – schnell, flexibel und skalierbar.
Sie haben eine Frage, eine Anregung oder möchten einfach nur mit den 4D Bloggern in Kontakt treten? Schreiben Sie uns eine Nachricht!
* Ihre Privatsphäre ist uns sehr wichtig. Bitte klicken Sie hier, um unsere Politik
Für diesen Beitrag sind derzeit keine Kommentare verfügbar.