
4D AI: 4D Vector のパワー
8月 1, 2025
1 読了時間

人工知能・自然言語処理・空間データを扱うような最新のアプリケーションにおいては、ベクトル計算が鍵となります。そのため、4D 20 R10 では 4D.Vector という新しいオブジェクトを導入しました。これは、デベロッパーが数行のコードでデータのベクトルを保存し、比較できるように設計されています。
たとえば、テキストプロンプトとの一致度に基づいて画像をランク付けする機能を構築する場合、ベクトルを生成し、コサイン類似度を使用してそれらを比較し、最も関連性の高いものから低いものへと結果を並べ替えるだけです。
人工知能の統合は単なるトレンドではなく、最新のビジネスアプリケーションの重要な原動力となりつつあります。そのため、4D はネイティブの AI機能に深く投資し、お客様をサポートしています。4D 20 R10 では、ベクトルデータのサポートが始まりました。 4D.Vector を導入し、4D 21 で提供されるより強力な機能セットへの土台を築きました。
この最初のリリースは、経験豊富なデベロッパーが、4Dアプリケーションで直接、よりスマートで AI を活用した機能を構築し始めるためのツールを提供します。しかし、それは始まりに過ぎません。パフォーマンスのスケーリングに不可欠なベクトル・インデックスのような重要な機能強化は、まだこれからです。それまでは、セマンティック検索や自然言語マッチングなど、現在可能なことを示す実際のユースケースにまず焦点を当てていきましょう。
ベクトルは単なる数値の羅列ですが、その数値は意味のあるものを表しています。
AI では、言葉や画像、あるいは顧客の行動といった複雑なものを、機械が比較できるように記述するためにベクトルを使用します。リストの各数値は、その物事が意味するもの、つまりそのトーン、スタイル、トピック、コンテキストなど、意味の一部を表しています。
たとえば、“apple” という単語は、[0.12, -0.45, 0.78, …] のようなベクトルになるかもしれません。これらの数値は、それが言葉の中でどのように使われているかを反映しており、文脈によって、果物に関連するかもしれないし、ハイテク企業に関連するかもしれません。
これらのベクトルは高次元空間に存在し、似たような意味は近く、関係のないものは遠く離れています。
この構造は比較をシンプルにします:
「この画像はそのプロンプトに概念的に近いか?」
「この 2つの文書は同じようなことを記述しているのか?」
コサイン類似度のようなベクトル演算を使って、2つのベクトルがどれだけ近いかを計算し、近ければ近いほど、意味の関連性が高いことになります。これが、セマンティック検索、おすすめ、分類のような最新の機能の仕組みです。
4D 20 R10 から、4D.Vector という新しいネイティブオブジェクトにより、コード内でベクトルを直接扱うことができるようになりました。
4D.Vector は、ベクトル演算をシンプルにし、アクセスしやすくするように設計されているので、外部ライブラリに依存することなく、高次元データの保存・比較・並べ替えができます。2つのアイテムがどれだけ似ているかを測定する必要がありますか? コサイン類似度、ドット積、ユークリッド距離を計算する専用のビルトイン関数を呼び出すだけです。
4D.Vector を作成する簡単な方法は 2つあります:
たとえば、概念の比較やセマンティック検索のために、テキストの一部をベクトルにしたい場合、4D AI Kit を通して OpenAI の埋め込みモデルを使うことができます:
var $AIKey:="tDGWULQsrG..."
var $clientAI:=cs.AIKit.OpenAI.new($AIKey)
var $inputText:="Apple"
// 使用する埋め込みモデルの名称
var $model:="text-embedding-ada-002"
// OpenAI の埋め込みAPI を呼び出して、入力テキストのベクトルを生成します
var $result:=$clientAI.embeddings.create($inputText; $model)
Var $myVector:=$result.embedding.vector
// $myVector=[0.013417294,-0.005096785,-0.001601552,-0.04005942,...]これにより、入力の意味を捉えた浮動小数点数のリストが得られます。これで、比較・ランキング・分類のタスクをおこなうことができます。
外部のサービスやモデルから取得したものなど、ベクトルデータがすでにある場合、4D.Vector を手動で作成することもできます:
var $vector := 4D.Vector.new([0.123; -0.456; 0.789])コサイン類似度は自然言語処理 (NLP) で最も広く使われている類似度メトリクスのひとつで、文章や文書の意味を比較するのに理想的です。2つのベクトルがどれだけ同じ方向を向いているかを、大きさではなく角度に基づいて測定します。

var $anotherVector := 4D.Vector.new([0.598; -0.951; 0.789])
var $similarity := $vector.cosineSimilarity($anotherVector)
// $similarity = 0,8949424061203範囲: –1 (反対) ~ 1 (同一)
最適な用途: 文章の埋め込み比較、セマンティック検索、文書分類など
ドット類似度 (スカラー積とも呼ばれる) は、ベクトルの方向と長さの両方を組み合わせます。つまり、2つのベクトルの方向性がどれだけ似ているかだけでなく、どれだけ強いかも見ることができます。
2つのベクトルが同じような方向を向いていて、かつ、長さが大きければ、図の太い矢印で示すように、ドット積は大きくなります。
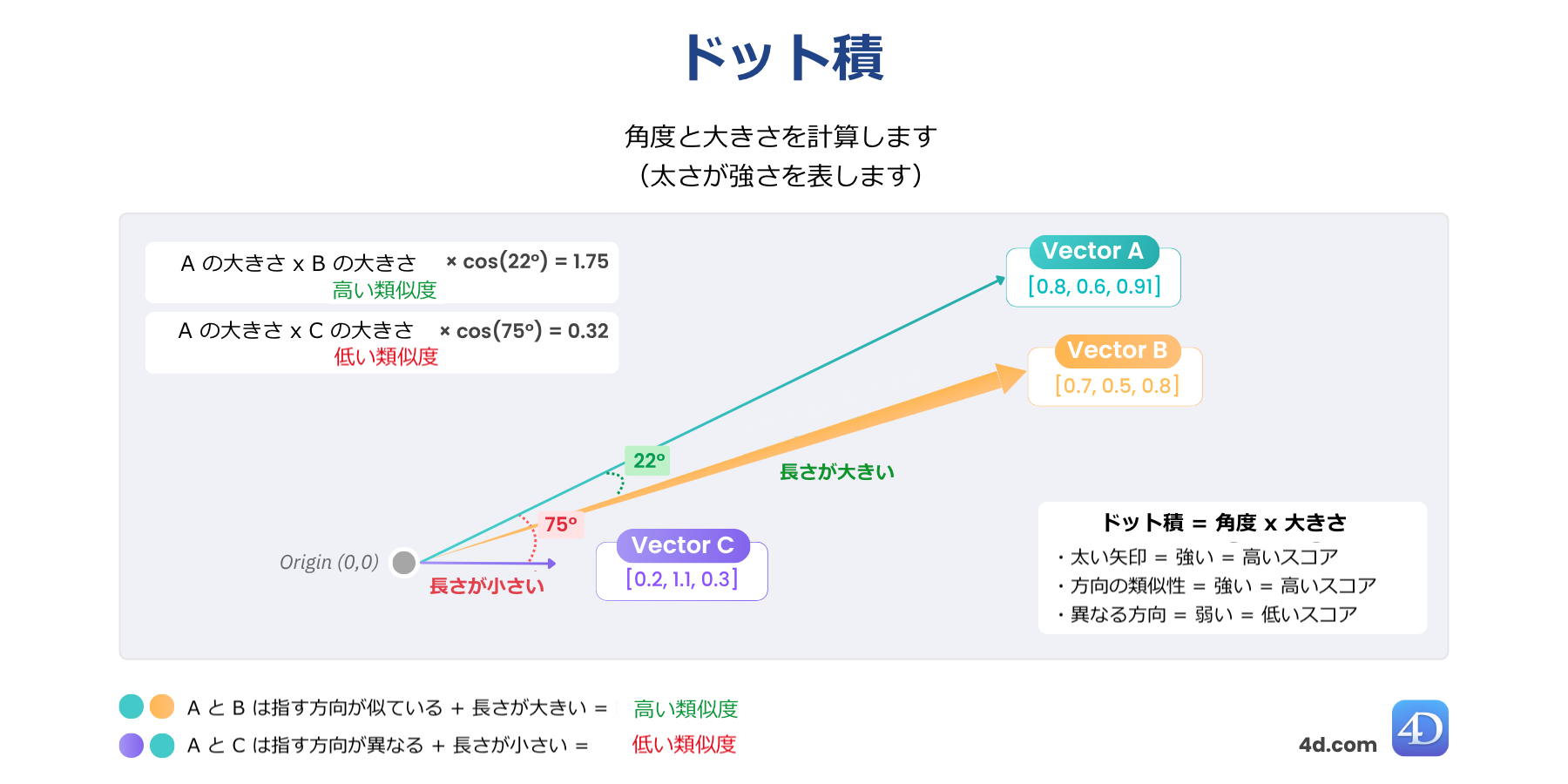
var $score := $vector.dotSimilarity($anotherVector)
// $score = 1,129731値が大きいほど類似性が高く、整合性が強いことを意味します。
最適な用途: レコメンドエンジン、Transformerモデル、埋め込みの微調整など
ユークリッド距離は、ベクトル間の直線距離を測り、2つのベクトルが空間の中でどれだけ離れているかを示します。遠ければ遠いほど、両者は異なっていると判断されます。
これは、相違度を測る必要がある場合に最適で、クラスタリング・異常検出・地理空間推論に理想的です。
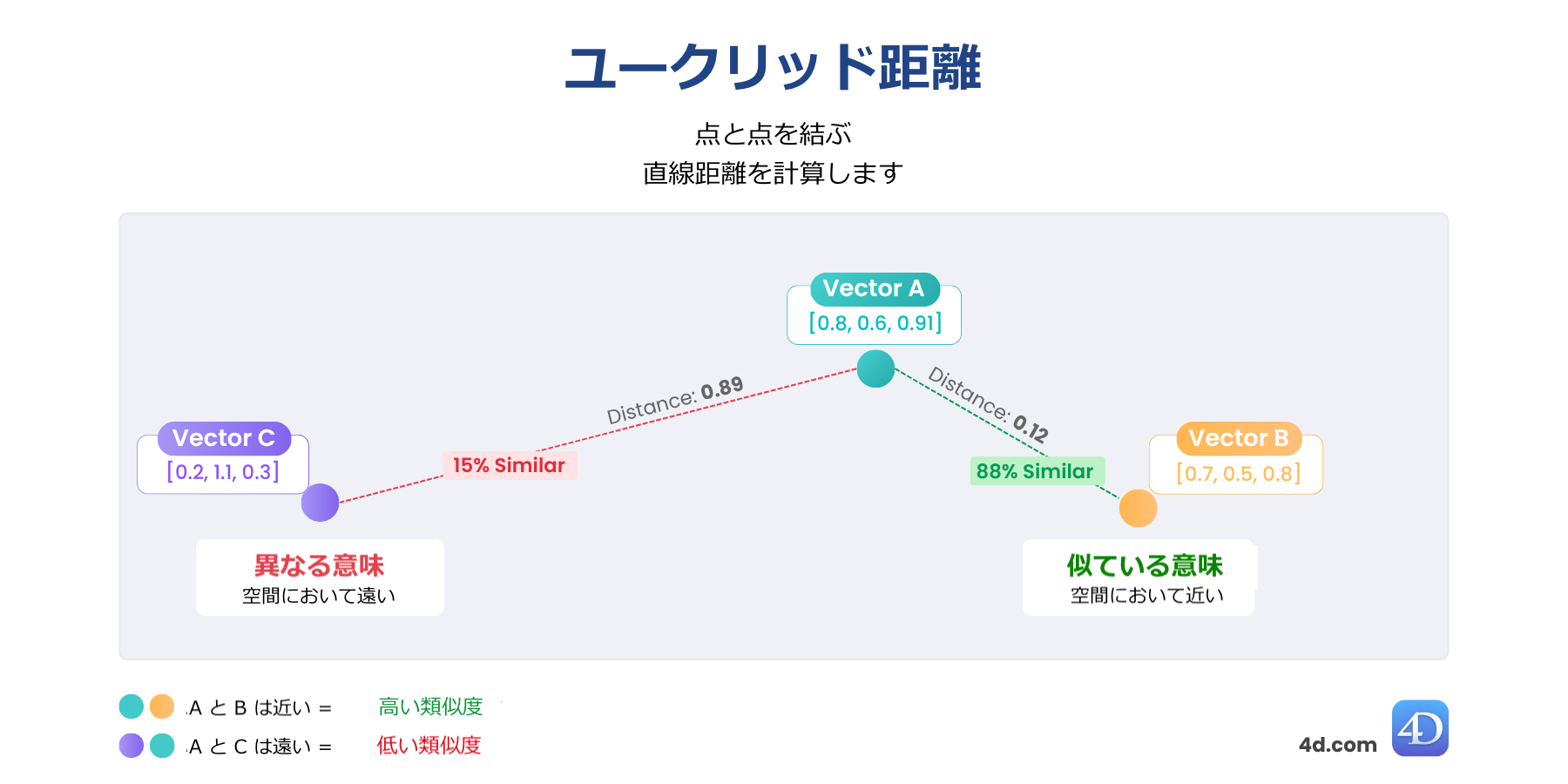
var $distance := $vector.euclideanDistance($anotherVector)
//$distance = 0,6860393574716より近い (数値が小さい) = より似ている
最適な用途: 構造化データ、異常検知、空間的近接性など

4D.Vector オブジェクトは、あなたのアプリケーションに新しい機能を提供するための土台を作ります。わずか数行のコードで、以下のことが可能になります:
意図を理解する検索ツールの構築
実際のコンテキストを利用したレコメンデーション
メタデータだけでなく、意味に基づいたデータのランク付け・グループ化・フィルタリング
そしてすべてが 4D でネイティブに動作し、高速で柔軟、スケーリングにも対応しています。
現在、この投稿へのコメント機能は利用できません。