
4D AI: Objevte sílu 4D vektorů
1 srpna, 2025
7 Čas na přečtení

Při práci s moderními aplikacemi, zejména s umělou inteligencí, zpracováním přirozeného jazyka nebo prostorovými daty, je vektorová matematika klíčová. Proto 4D 20 R10 zavádí nový objekt: 4D.Vector, který vývojářům pomáhá ukládat a porovnávat vektory dat pomocí několika málo řádků kódu.
Pokud například vytváříte funkci pro hodnocení obrázků na základě toho, jak dobře odpovídají textové výzvě, stačí vygenerovat vektory, porovnat je pomocí kosinové podobnosti a seřadit výsledky od nejrelevantnějšího po nejméně relevantní, a to vše přímo ve 4D.
Integrace umělé inteligence není jen trendem – stává se klíčovou hnací silou moderních podnikových aplikací. Proto společnost 4D hluboce investuje do nativních funkcí umělé inteligence, aby vás podpořila. S verzí 4D 20 R10 začíná podpora vektorových dat zavedením funkce 4D.Vector – a položila tak základ pro výkonnější sadu funkcí, která přijde v 4D 21.
Tato první verze poskytuje zkušeným vývojářům nástroje, které jim umožní začít vytvářet chytřejší funkce využívající umělou inteligenci přímo v aplikacích 4D. Je to však teprve začátek. Klíčová vylepšení, jako je vektorový index – zásadní pro škálování výkonu – teprve přijdou. Mezitím se zaměřujeme na reálné případy použití, které ukazují, co je dnes možné, včetně sémantického vyhledávání a porovnávání v přirozeném jazyce.
Vektor je ve své podstatě jen seznam čísel, která však představují něco smysluplného.
V umělé inteligenci používáme vektory k popisu složitých věcí, jako jsou slova, obrázky nebo dokonce chování zákazníků, způsobem, který mohou stroje porovnávat. Každé číslo v seznamu zachycuje část toho, co daná věc znamená: její tón, styl, téma nebo kontext.
Například slovo „jablko“ se může stát vektorem jako [0,12, -0,45, 0,78, …]. Tato čísla odrážejí, jak se používá v jazyce, možná se vztahuje k ovoci, možná k technologické společnosti, v závislosti na kontextu.
Tyto vektory žijí ve vysokodimenzionálním prostoru, kde jsou podobné významy blízko sebe a nesouvisející věci daleko od sebe.
Díky této struktuře je porovnávání jednoduché:
„Je tento obrázek pojmově blízký tomuto podnětu?“.
„Hovoří tyto dva dokumenty o stejné věci?“.
K měření toho, jak blízko si jsou dva vektory, používáme vektorovou matematiku, například kosinovou podobnost. Čím jsou si bližší, tím je jejich význam příbuznější. Tak fungují moderní funkce, jako je sémantické vyhledávání, doporučení a klasifikace.
Od verze 4D v20 R10 můžete nyní pracovat s vektory přímo v kódu díky novému nativnímu objektu: 4D.Vector.
Je navržen tak, aby vektorová matematika byla jednoduchá a přístupná, takže můžete ukládat, porovnávat a třídit vysokodimenzionální data, aniž byste se museli spoléhat na externí knihovny. Potřebujete změřit, jak moc jsou si dvě položky podobné? Stačí zavolat vestavěné metody, jako je kosinová podobnost, bodový součin nebo euklidovská vzdálenost, a to vše přímo uvnitř 4D.
Existují dva jednoduché způsoby, jak vytvořit 4D.Vector, v závislosti na tom, odkud vaše data pocházejí:
Pokud chcete z části textu vytvořit vektor, například pro porovnání myšlenek nebo pro výkon sémantického vyhledávání, můžete použít model vkládání OpenAI prostřednictvím sady 4D AI Kit:
var $AIKey:="tDGWULQsrG..."
var $clientAI:=cs.AIKit.OpenAI.new($AIKey)
var $inputText:="Apple"
// Name of the embedding model to use
var $model:="text-embedding-ada-002"
// Call the OpenAI embeddings API to generate the vector for the input text
var $result:=$clientAI.embeddings.create($inputText; $model)
Var $myVector:=$result.embedding.vector
// $myVector=[0.013417294,-0.005096785,-0.001601552,-0.04005942,...]Ten vám poskytne seznam čísel s pohyblivou řádovou čárkou, která vystihují význam vašeho vstupu. Nyní je můžete použít při porovnávání, řazení nebo klasifikačních úlohách.
Pokud již máte k dispozici vektorová data – třeba z externí služby nebo modelu – můžete vytvořit 4D.Vector ručně:
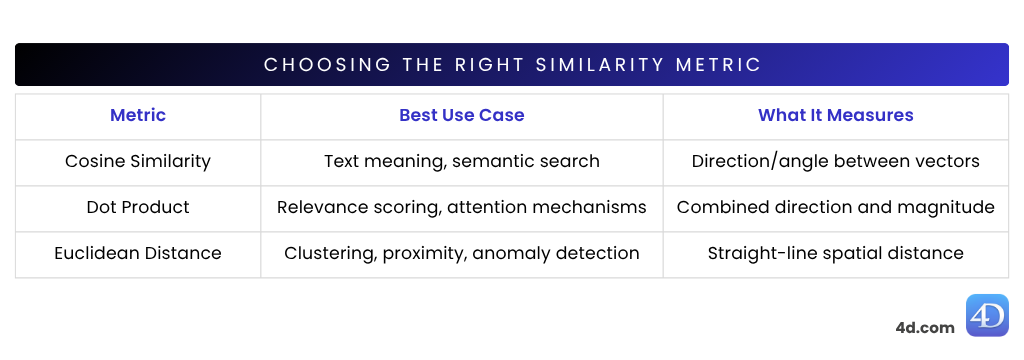
var $vector := 4D.Vector.new([0.123; -0.456; 0.789])Kosinová podobnost je jednou z nejpoužívanějších metrik podobnosti ve zpracování přirozeného jazyka (NLP) – ideální pro porovnávání významu vět nebo dokumentů. Měří, jak blízko k sobě dva vektory směřují, a to na základě úhlu mezi nimi, nikoli jejich velikosti.

var $anotherVector := 4D.Vector.new([0.598; -0.951; 0.789])
var $similarity := $vector.cosineSimilarity($anotherVector)
// $similarity = 0,8949424061203Rozsah: -1 (opačný) až 1 (shodný).
Skvělé pro: porovnávání vložených vět, sémantické vyhledávání a klasifikaci dokumentů.
Bodová podobnost (nazývaná také skalární součin) kombinuje směr i délku vektorů. To znamená, že nezkoumá pouze to, jak jsou dva vektory zarovnané, ale také jak jsou silné.
Pokud dva vektory směřují podobným směrem a mají velkou velikost, bude bodový součin vysoký, což ukazují silnější šipky v diagramu.
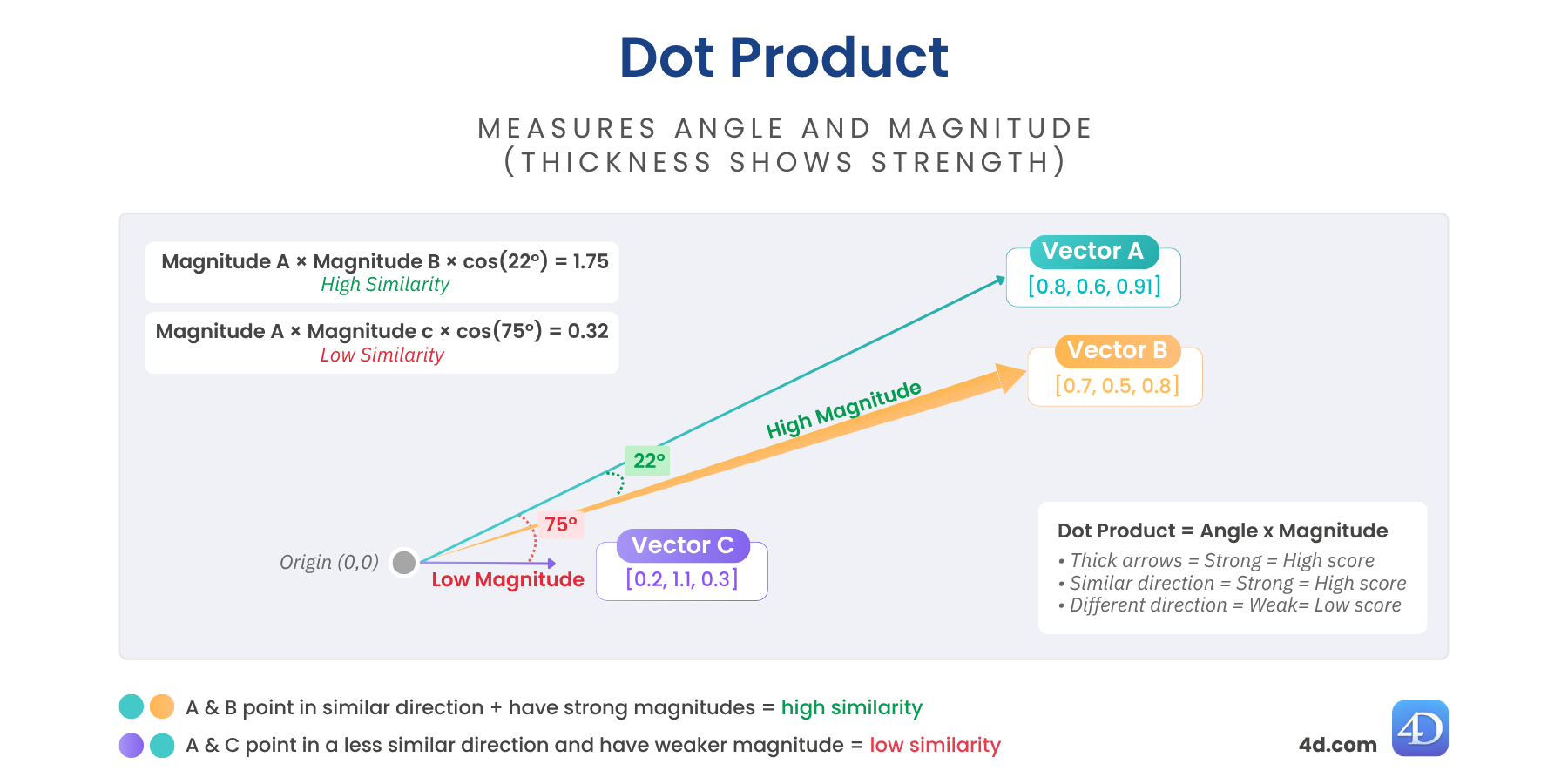
var $score := $vector.dotSimilarity($anotherVector)
// $score = 1,129731Vyšší hodnoty = větší podobnost a silnější zarovnání.
Skvěle se hodí pro: doporučovací stroje, transformační modely, jemně vyladěná usazení.
Euklidovská vzdálenost poskytuje skutečnou míru „jako moucha“ mezi vektory. Ukazuje, jak daleko od sebe jsou dva vektory v prostoru – čím jsou si blíže, tím je jejich význam podobnější. Čím jsou od sebe vzdálenější, tím jsou rozdílnější.
Je ideální, když potřebujete skutečnou míru nepodobnosti – ideální pro shlukování, detekci anomálií nebo geoprostorové uvažování.
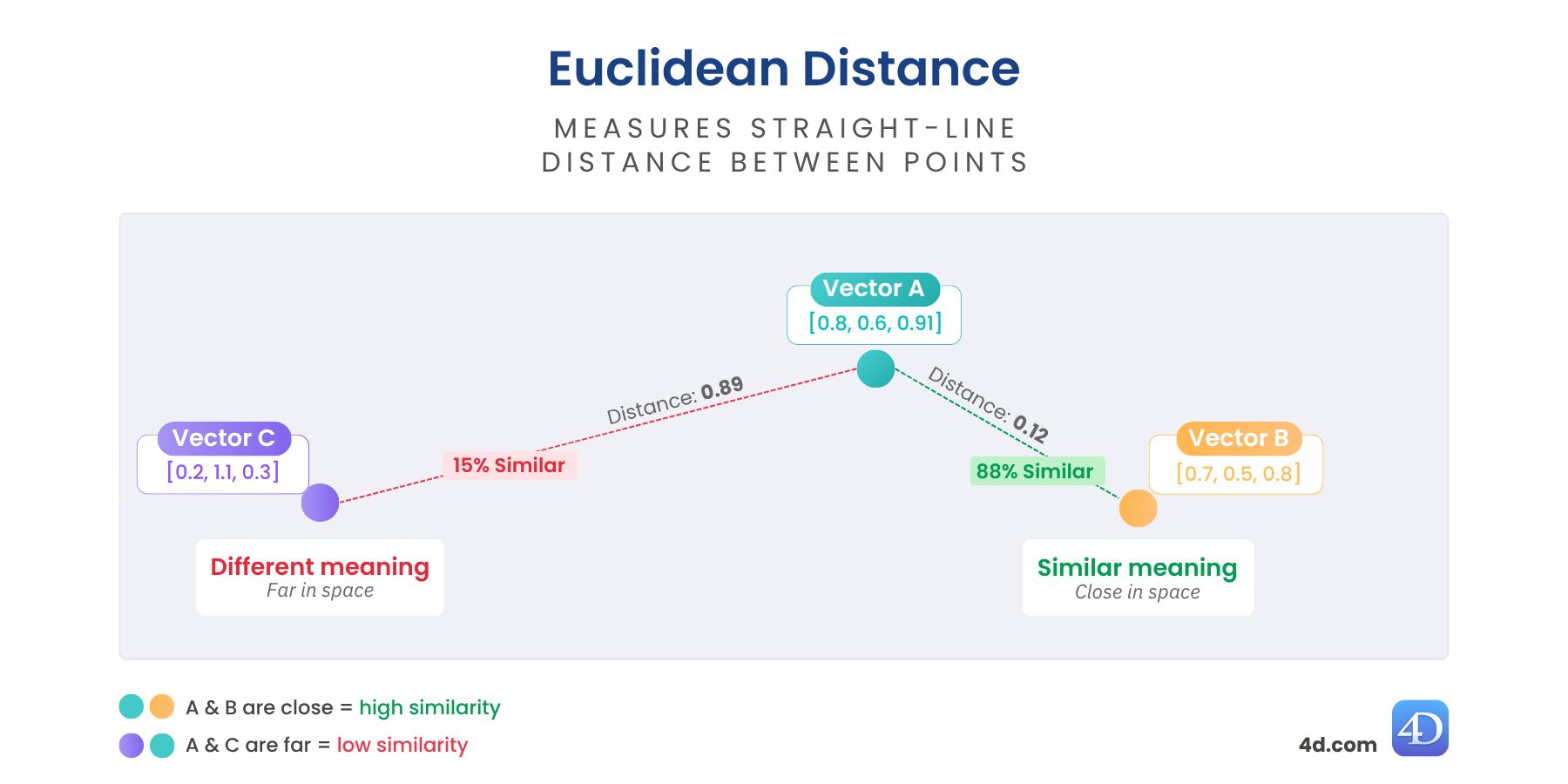
var $distance := $vector.euclideanDistance($anotherVector)
//$distance = 0,6860393574716Nižší = podobnější
Skvělé pro: strukturovaná data, detekci anomálií nebo prostorovou blízkost.
. 4D.Vector Objekt položí základ pro celou řadu nových funkcí ve vašich aplikacích. Stačí jen několik řádků kódu a můžete:
vytvářet vyhledávací nástroje, které rozumí záměru
Poskytovat doporučení se skutečným kontextem
řadit, seskupovat a filtrovat data na základě významu, nikoliv pouze metadat
A to vše běží nativně v prostředí 4D – rychle, flexibilně a připraveně na škálování.
Máte dotaz, návrh nebo se chcete spojit s blogery 4D? Napište nám!
* Vaše soukromí je pro nás velmi důležité. Kliknutím sem si můžete prohlédnout naše Zásady
K tomuto příspěvku zatím nelze přidávat komentáře.