
4D AI: descubra el poder de los vectores 4D
agosto 1, 2025
6 tiempo de lectura

Cuando se trabaja con aplicaciones modernas, especialmente aquellas que involucran Inteligencia Artificial, procesamiento de lenguaje natural o datos espaciales, la matemática vectorial es clave. Por eso 4D 20 R10 introduce un nuevo objeto: 4D.Vector, diseñado para ayudar a los desarrolladores a almacenar y comparar vectores de datos con sólo unas pocas líneas de código.
Por ejemplo, si está creando una funcionalidad para clasificar imágenes basándose en lo bien que coinciden con un texto, simplemente genere vectores, compárelos usando la similitud coseno, y ordene sus resultados de más a menos relevante, todo directamente en 4D.
La integración de la inteligencia artificial no es sólo una tendencia, se está convirtiendo en un factor clave para las aplicaciones profesionales modernas. Es por eso que 4D está invirtiendo profundamente en capacidades nativas de IA para apoyarlo. Con 4D 20 R10, el soporte para datos vectoriales comienza con la introducción de 4D.Vector, sentando las bases para un conjunto de funcionalidades más poderosas que llegarán en 4D 21.
Esta primera versión da a los desarrolladores experimentados las herramientas para empezar a crear funciones más inteligentes, impulsadas por la IA directamente en sus aplicaciones 4D. Pero esto es sólo el principio. Mejoras clave como un índice vectorial – esencial para escalar el rendimiento – están aún por llegar. Mientras tanto, nos centramos en casos de uso reales que muestran las posibilidades actuales, como la búsqueda semántica y la correspondencia de lenguaje natural.
En esencia, un vector no es más que una lista de números, pero esos números representan algo significativo.
En IA, utilizamos vectores para describir cosas complejas como palabras, imágenes o incluso el comportamiento de los clientes de una forma que las máquinas puedan comparar. Cada número de la lista capta parte de lo que esa cosa significa: su tono, estilo, tema o contexto.
Por ejemplo, la palabra «manzana» puede convertirse en un vector como [0,12, -0,45, 0,78, …]. Esos números reflejan cómo se utiliza en el lenguaje, quizá relacionado con la fruta, quizá con la empresa tecnológica, según el contexto.
Estos vectores viven en un espacio de alta dimensión, en el que los significados similares están cerca unos de otros y las cosas no relacionadas están lejos.
Esta estructura simplifica las comparaciones:
«¿Esta imagen es conceptualmente parecida a ese mensaje?
«¿Estos dos documentos hablan de lo mismo?».
Utilizamos matemáticas vectoriales, como la similitud del coseno, para medir lo cerca que están dos vectores. Cuanto más cercanos estén, más relacionado estará su significado. Así es como funcionan funciones modernas como la búsqueda semántica, las recomendaciones y la clasificación.
A partir de 4D 20 R10, ahora puede trabajar con vectores directamente en su código gracias a un nuevo objeto nativo: 4D.Vector.
Está diseñado para hacer las matemáticas vectoriales simples y accesibles para que pueda almacenar, comparar y ordenar datos de alta dimensión sin depender de librerías externas. ¿Necesita medir la similitud entre dos elementos? Sólo tiene que llamar a los métodos integrados como la similitud coseno, el producto punto, o la distancia euclidiana, todo al interior de 4D.
Hay dos formas sencillas de crear un vector 4D.Vector dependiendo de la procedencia de los datos:
Si quiere transforma un texto en un vector, por ejemplo, para comparar ideas o potenciar la búsqueda semántica, puede utilizar el modelo de integración de OpenAI a través de 4D AI Kit:
var $AIKey:="tDGWULQsrG..."
var $clientAI:=cs.AIKit.OpenAI.new($AIKey)
var $inputText:="Apple"
// Name of the embedding model to use
var $model:="text-embedding-ada-002"
// Call the OpenAI embeddings API to generate the vector for the input text
var $result:=$clientAI.embeddings.create($inputText; $model)
Var $myVector:=$result.embedding.vector
// $myVector=[0.013417294,-0.005096785,-0.001601552,-0.04005942,...]Esto le da una lista de números de punto flotante que capturan el significado de su entrada. Ahora puede utilizarlo en tareas de comparación, ranking o clasificación.
Si ya dispone de datos vectoriales – tal vez de un servicio o modelo externo – puede crear un modelo vectorial 4D.Vector manualmente:
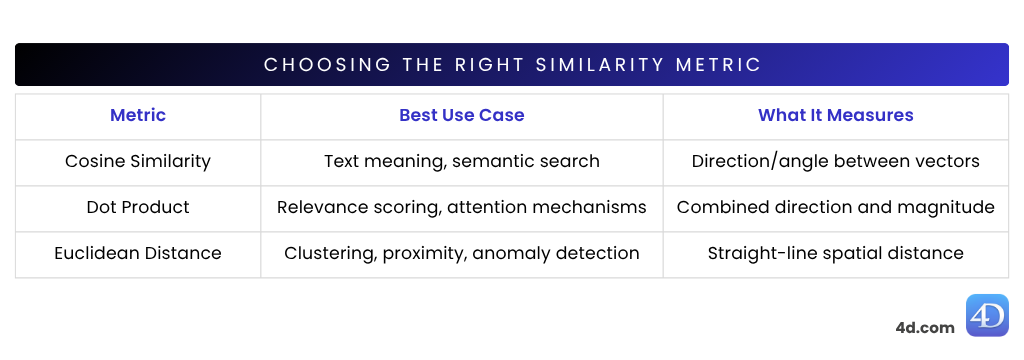
var $vector := 4D.Vector.new([0.123; -0.456; 0.789])La similitud coseno es una de las métricas de similitud más utilizadas en el procesamiento del lenguaje natural (NLP), ideal para comparar el significado de frases o documentos. Mide hasta qué punto dos vectores apuntan en la misma dirección, basándose en el ángulo entre ellos, no en su tamaño.

var $anotherVector := 4D.Vector.new([0.598; -0.951; 0.789])
var $similarity := $vector.cosineSimilarity($anotherVector)
// $similarity = 0,8949424061203Intervalo: -1 (opuesto) a 1 (idéntico)
Ideal para: comparar incrustaciones de frases, búsqueda semántica y clasificación de documentos
La similitud de puntos (también llamada producto escalar) combina la dirección y la longitud de los vectores. Esto significa que no sólo se fija en lo alineados que están dos vectores, sino también en lo fuertes que son.
Si dos vectores apuntan en una dirección similar y tienen magnitudes grandes, el producto escalar será alto, como muestran las flechas más gruesas del diagrama.
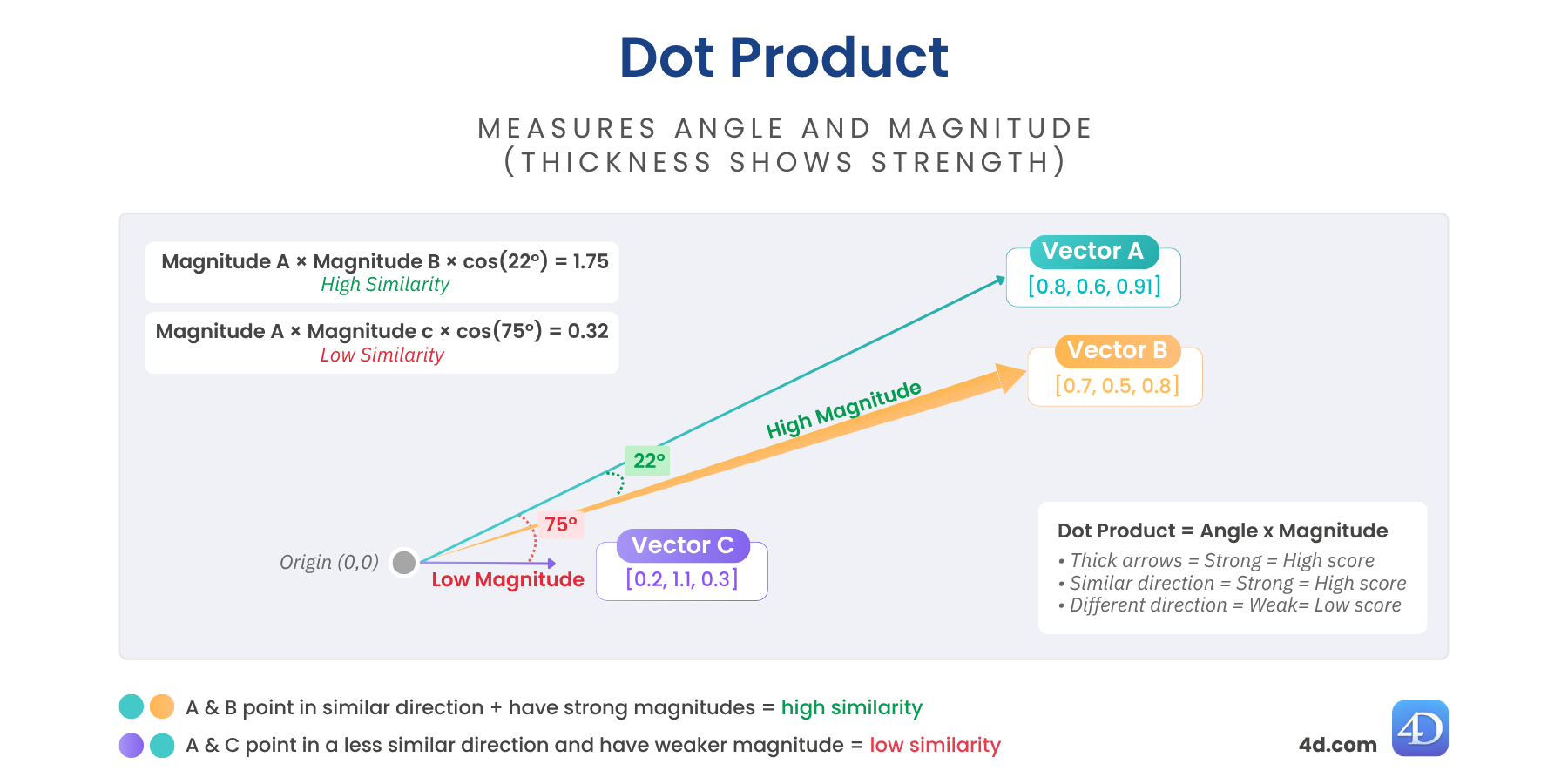
var $score := $vector.dotSimilarity($anotherVector)
// $score = 1,129731Valores más altos = más similitud y alineación más fuerte.
Ideal para: motores de recomendación, modelos transformadores, incrustaciones ajustadas.
La distancia euclídea proporciona una medida real entre vectores. Muestra lo alejados que están dos vectores en el espacio: cuanto más cerca están, más similar es su significado. Cuanto más alejados, más diferentes.
Es perfecta cuando se necesita una medida real de disimilitud, ideal para la agrupación, la detección de anomalías o el razonamiento geoespacial.
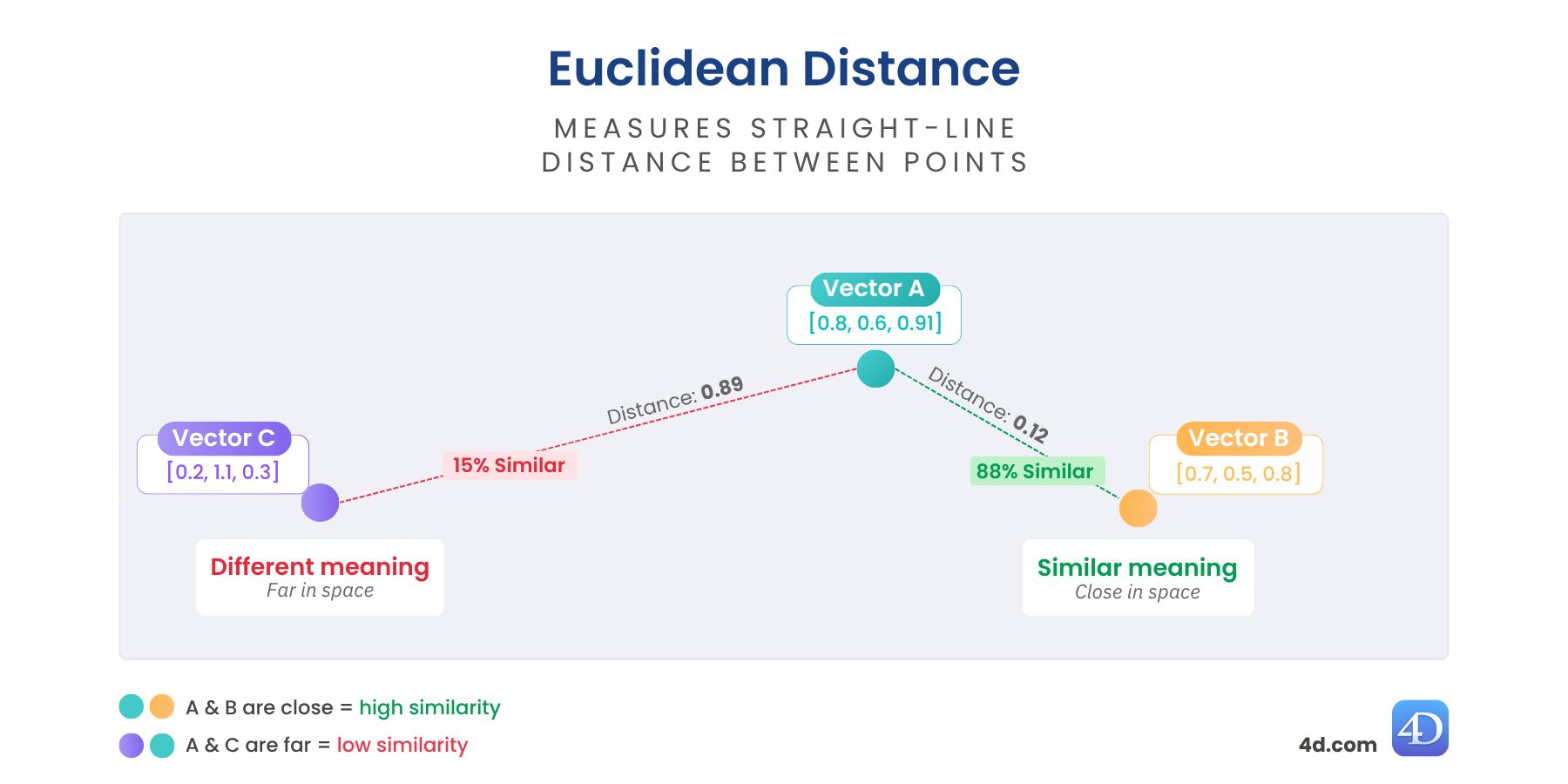
var $distance := $vector.euclideanDistance($anotherVector)
//$distance = 0,6860393574716Más bajo = más similar
Ideal para: datos estructurados, detección de anomalías o proximidad espacial
El objeto 4D.Vector sienta las bases para un nuevo conjunto de funciones en sus aplicaciones. Con sólo unas pocas líneas de código, puede:
Crear herramientas de búsqueda que entiendan la intención
Potenciar recomendaciones con contexto real
Clasificar, agrupar y filtrar datos basándose en el significado, no sólo en metadatos
Y todo se ejecuta de forma nativa en 4D – rápido, flexible y listo para escalar.
¿Tiene alguna pregunta, sugerencia o simplemente quiere ponerse en contacto con los bloggers de 4D? Escríbenos.
* Su privacidad es muy importante para nosotros. Haga clic aquí para ver nuestra Política
Por el momento, no se pueden publicar comentarios en esta entrada.