
4D AI : Découvrez la puissance des vecteurs 4D
août 1, 2025
7 min de lecture

Lorsque l’on travaille avec des applications modernes, en particulier celles qui impliquent l’intelligence artificielle, le traitement du langage naturel ou les données spatiales, les mathématiques vectorielles sont essentielles. C’est pourquoi 4D 20 R10 introduit un nouvel objet : 4D.Vector. L’objet Vector, conçu pour aider les développeurs à stocker et à comparer des vecteurs de données avec seulement quelques lignes de code.
Par exemple, si vous créez une fonctionnalité pour classer des images en fonction de leur correspondance avec un texte, il vous suffit de générer des vecteurs, de les comparer en utilisant la similarité cosinusoïdale et de trier vos résultats du plus pertinent au moins pertinent, le tout directement dans 4D.
L’intégration de l’intelligence artificielle n’est pas seulement une tendance, elle devient un facteur clé pour les applications d’entreprise modernes. C’est pourquoi 4D investit massivement dans des capacités d’IA natives pour vous aider. Avec 4D v20 R10, la prise en charge des données vectorielles commence par l’introduction de l’intelligence artificielle: 4D.Vector, jetant les bases d’un ensemble de fonctionnalités plus puissantes à venir dans 4D 21.
Cette première version donne aux développeurs expérimentés les outils nécessaires pour commencer à créer des fonctions plus intelligentes, alimentées par l’IA, directement dans leurs applications 4D. Mais ce n’est que le début. Des améliorations clés telles que l’index vectoriel – essentiel pour la mise à l’échelle des performances – sont encore à venir. En attendant, nous nous concentrons sur des cas d’utilisation réels qui montrent ce qui est possible aujourd’hui, notamment la recherche sémantique et la correspondance en langage naturel.
À la base, un vecteur n’est qu’une liste de nombres, mais ces nombres représentent quelque chose de significatif.
En IA, nous utilisons des vecteurs pour décrire des éléments complexes tels que des mots, des images ou même le comportement des clients d’une manière que les machines peuvent comparer. Chaque nombre de la liste capture une partie de la signification de cette chose : son ton, son style, son sujet ou son contexte.
Par exemple, le mot « pomme » peut devenir un vecteur comme [0,12, -0,45, 0,78, …]. Ces chiffres reflètent la façon dont il est utilisé dans le langage, qu’il s’agisse d’un fruit ou d’une entreprise technologique, en fonction du contexte.
Ces vecteurs vivent dans un espace à haute dimension, où les significations similaires sont proches les unes des autres et où les choses sans rapport sont éloignées les unes des autres.
Cette structure facilite les comparaisons :
Cette structure facilite les comparaisons : « Cette image est-elle conceptuellement proche de ce message ? »
« Ces deux documents parlent-ils de la même chose ? »
Nous utilisons les mathématiques vectorielles, comme la similarité cosinusoïdale, pour mesurer la proximité de deux vecteurs. Plus ils sont proches, plus leur sens est apparenté. C’est ainsi que fonctionnent les fonctionnalités modernes telles que la recherche sémantique, les recommandations et la classification.
À partir de 4D 20 R10, vous pouvez désormais travailler avec des vecteurs directement dans votre code grâce à un nouvel objet natif : 4D.Vector.
Il est conçu pour rendre les mathématiques vectorielles simples et accessibles afin que vous puissiez stocker, comparer et trier des données à haute dimension sans dépendre de bibliothèques externes. Vous avez besoin de mesurer la similarité de deux objets ? Il suffit d’appeler des méthodes intégrées telles que la similitude de cosinus, le produit de point ou la distance euclidienne, le tout à l’intérieur de 4D.
Il existe deux façons simples de créer un vecteur 4D.Vectorselon l’origine de vos données :
Si vous souhaitez transformer un texte en vecteur, par exemple pour comparer des idées ou effectuer une recherche sémantique, vous pouvez utiliser le modèle d’intégration d’OpenAI via 4D AI Kit :
var $AIKey:="tDGWULQsrG..."
var $clientAI:=cs.AIKit.OpenAI.new($AIKey)
var $inputText:="Apple"
// Name of the embedding model to use
var $model:="text-embedding-ada-002"
// Call the OpenAI embeddings API to generate the vector for the input text
var $result:=$clientAI.embeddings.create($inputText; $model)
Var $myVector:=$result.embedding.vector
// $myVector=[0.013417294,-0.005096785,-0.001601552,-0.04005942,...]Vous obtenez ainsi une liste de nombres à virgule flottante qui capturent le sens de votre entrée. Vous pouvez maintenant l’utiliser dans des comparaisons, des classements ou des tâches de classification.
Si vous disposez déjà de données vectorielles – provenant peut-être d’un service ou d’un modèle externe – vous pouvez créer un modèle vectoriel manuellement. 4D.Vector manuellement :
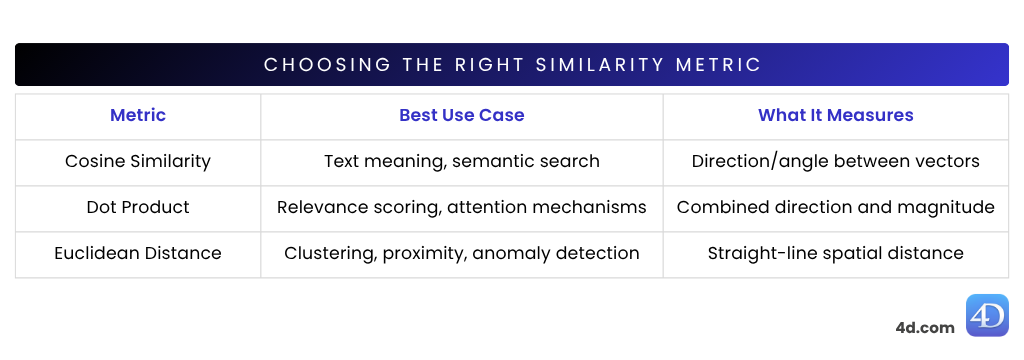
var $vector := 4D.Vector.new([0.123; -0.456; 0.789])La similarité cosinus est l’une des mesures de similarité les plus utilisées dans le traitement du langage naturel (NLP). Elle est idéale pour comparer le sens des phrases ou des documents. Elle mesure à quel point deux vecteurs pointent dans la même direction, en se basant sur l’angle entre eux, et non sur leur taille.

var $anotherVector := 4D.Vector.new([0.598; -0.951; 0.789])
var $similarity := $vector.cosineSimilarity($anotherVector)
// $similarity = 0,8949424061203Plage : -1 (opposé) à 1 (identique)
Idéal pour : la comparaison d’enchâssements de phrases, la recherche sémantique et la classification de documents.
La similarité de points (également appelée produit scalaire) combine à la fois la direction et la longueur des vecteurs. Cela signifie qu’elle ne se contente pas d’examiner l’alignement de deux vecteurs, mais aussi leur force.
Si deux vecteurs pointent dans une direction similaire et ont des amplitudes importantes, le produit de point sera élevé, comme le montrent les flèches plus épaisses dans le diagramme.
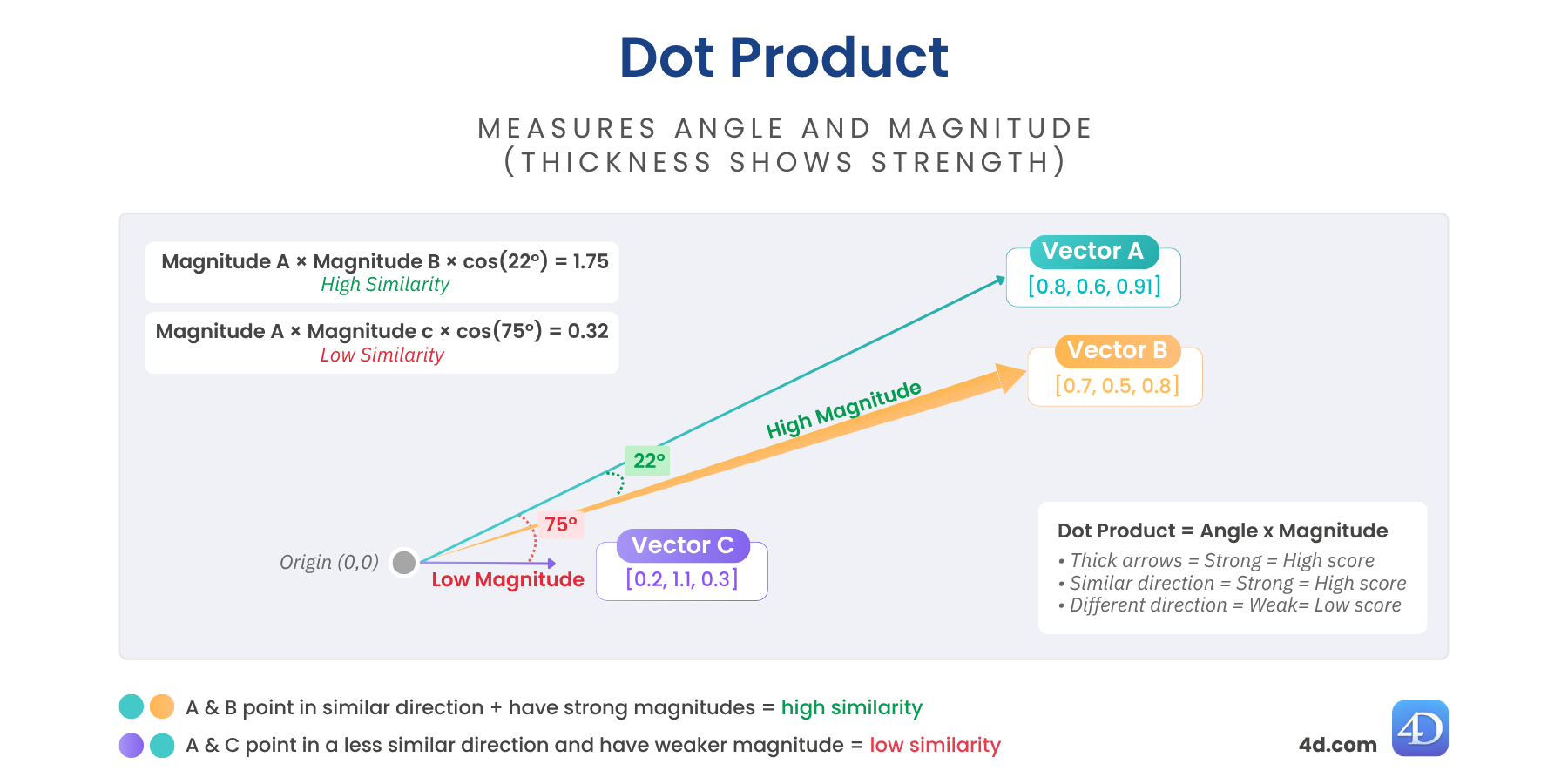
var $score := $vector.dotSimilarity($anotherVector)
// $score = 1,129731Plus les valeurs sont élevées, plus la similitude est grande et plus l’alignement est fort.
Idéal pour : les moteurs de recommandation, les modèles de transformation, les embeddings affinés.
La distance euclidienne vous donne une mesure réelle entre les vecteurs. Elle indique la distance qui sépare deux vecteurs dans l’espace – plus ils sont proches, plus leur signification est similaire. Plus ils sont éloignés, plus ils sont différents.
Cette mesure est parfaite lorsque vous avez besoin d’une véritable mesure de dissimilarité – idéale pour le clustering, la détection d’anomalies ou le raisonnement géospatial.
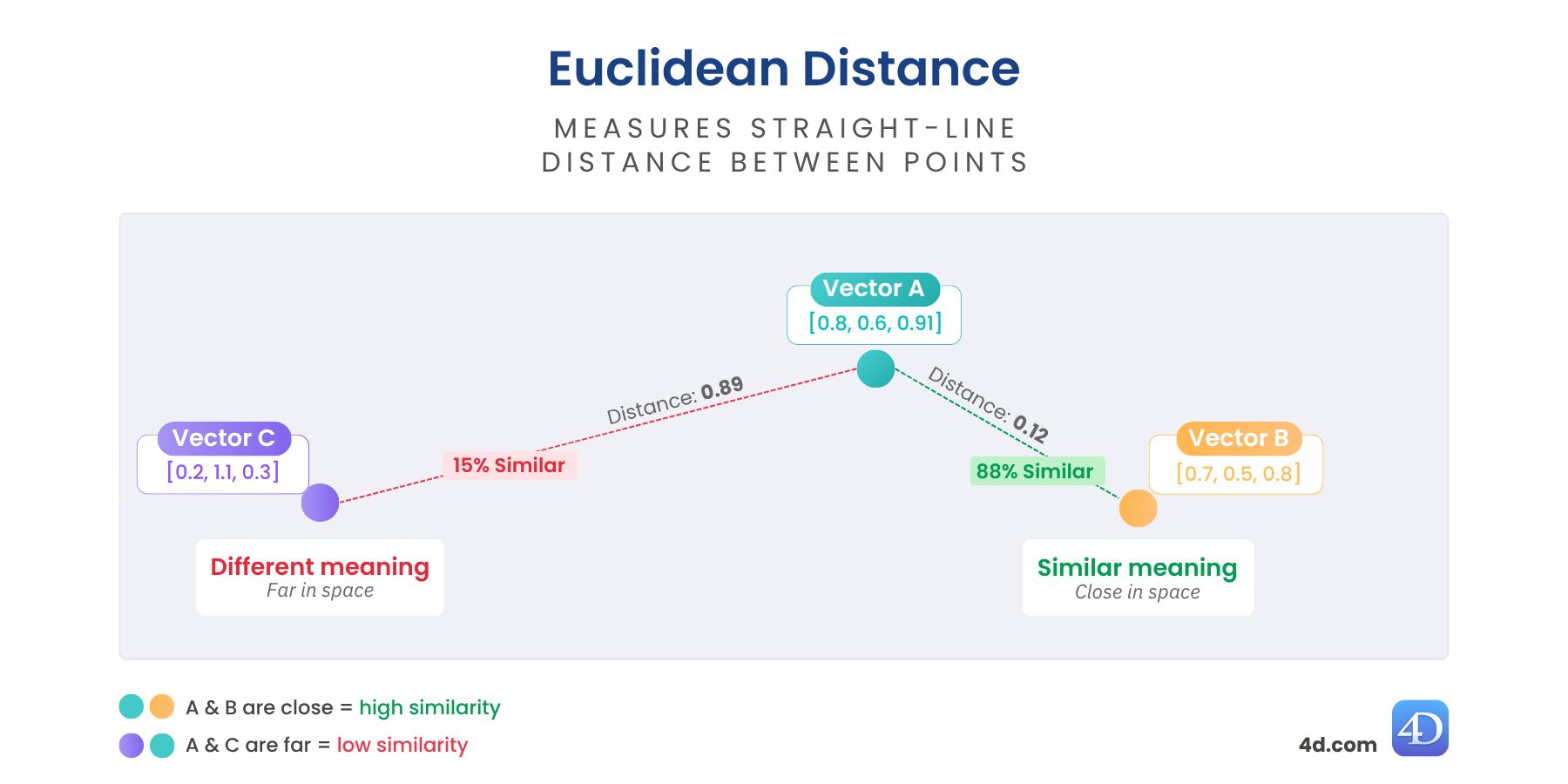
var $distance := $vector.euclideanDistance($anotherVector)
//$distance = 0,6860393574716Plus bas = plus similaire
Idéal pour : les données structurées, la détection d’anomalies ou la proximité spatiale
L’objet 4D.Vector jette les bases d’un ensemble de nouvelles fonctionnalités dans vos applications. Avec seulement quelques lignes de code, vous pouvez
Construire des outils de recherche qui comprennent l’intention
Alimenter les recommandations avec un contexte réel
Classer, grouper et filtrer les données en fonction de leur signification, et pas seulement des métadonnées.
Et tout cela fonctionne nativement dans 4D: rapide, flexible et prêt à évoluer.
Vous avez une question, une suggestion ou vous voulez simplement entrer en contact avec les blogueurs 4D ? Envoyez-nous un message !
* Votre vie privée est très importante pour nous. Veuillez cliquer ici pour consulter notre Politique
Les commentaires ne sont pas disponibles pour cet article pour le moment.