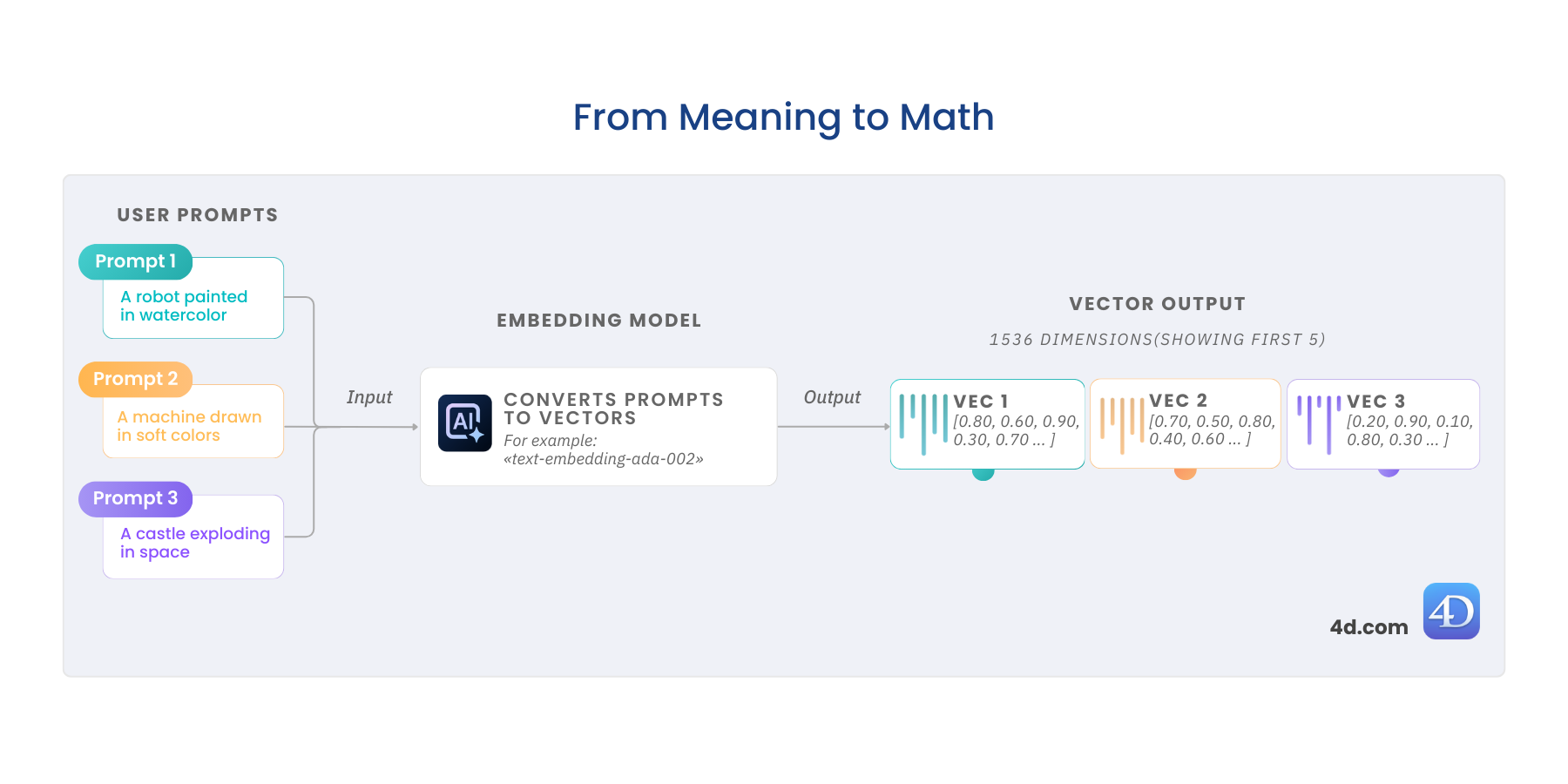
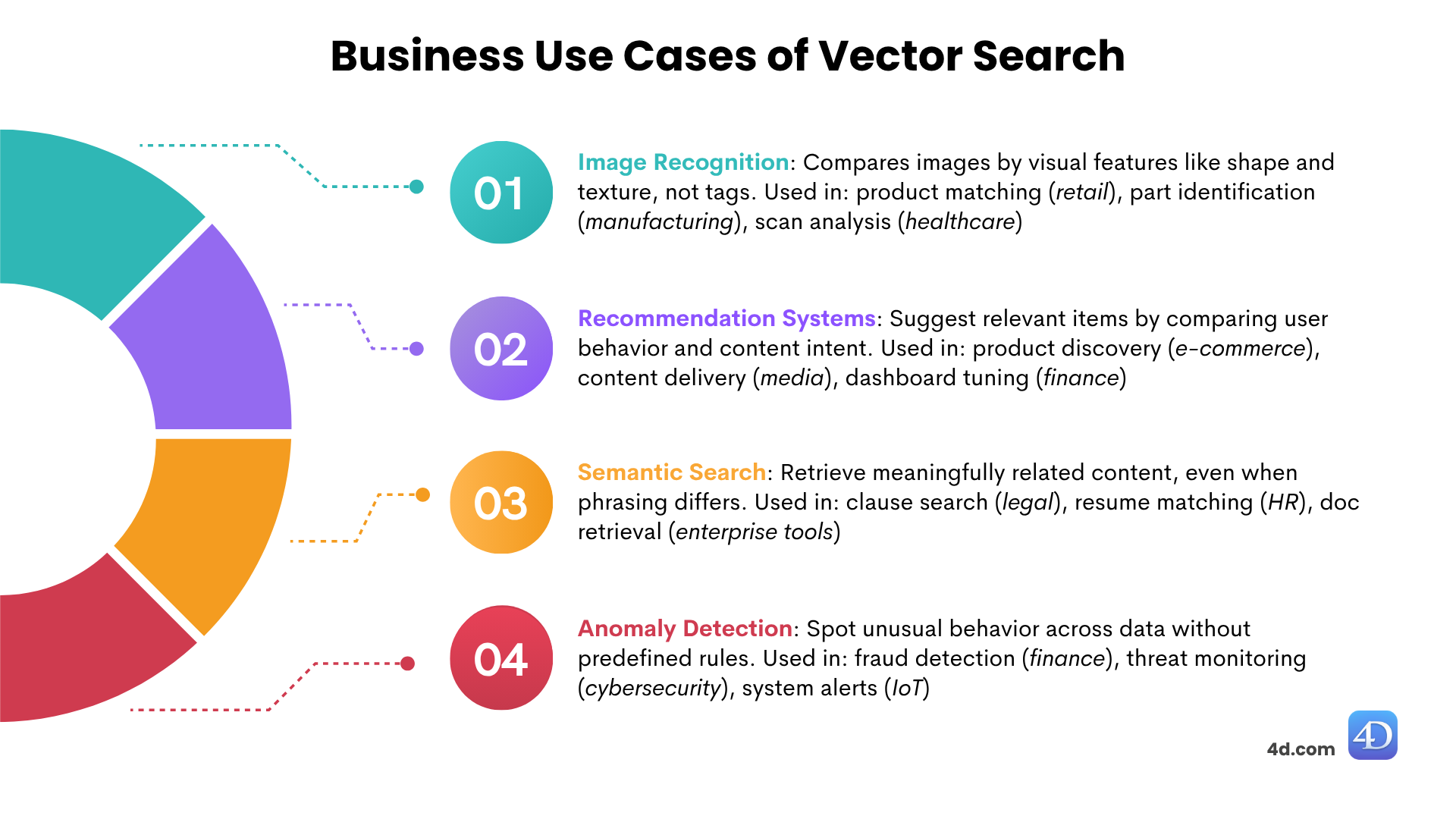
4D AI: Třídění výsledků dotazů podle podobnosti vektorů
V příspěvku Sémantické vyhledávání: dotazování podle vektorové podobnosti jsme představili, jak dotazovat entity pomocí vektorové podobnosti, což je ú...
20 ledna, 2026
1 Čas na přečtení